
目录
上文我们深入理解了 Elasticsearch 的架构与实现原理,通过倒排索引实现了搜索,你是否考虑过关键词的搜索中,其中关键词是如何从文档中拆分的呢?这实际上是通过分词器实现的,然而,在处理中文文本时,Elasticsearch 内置的标准分词器往往表现不佳,它会将句子逐字分割,无法理解词汇的边界,导致搜索准确率低下。
例如,句子 "我是中国人" 会被拆分为 "我","是","中","国","人" 这五个独立的字。当用户搜索 "中国" 时,可能无法精准匹配到这条文档。
IK 分词器 正是为了解决这一问题而生的。它是 Elasticsearch 的一款开源中文分词插件,提供了智能、细粒度的中文分词能力,并支持丰富的自定义词典,从而极大地提升了中文搜索的准确性和用户体验。接下来本文将手把手带你完成从 Elasticsearch 环境搭建到 IK 分词器集成的全过程。
Elasticsearch 环境搭建
我们首先在本地搭建一个 Elasticsearch 服务,通过使用 Docker 快速部署,Docker 方式能实现环境隔离,部署简单快捷,特别适合开发和测试环境。
拉取并运行 Elasticsearch 容器
创建es的网络环境
shdocker network create es-net
拉取镜像
shdocker pull elasticsearch:7.16.3
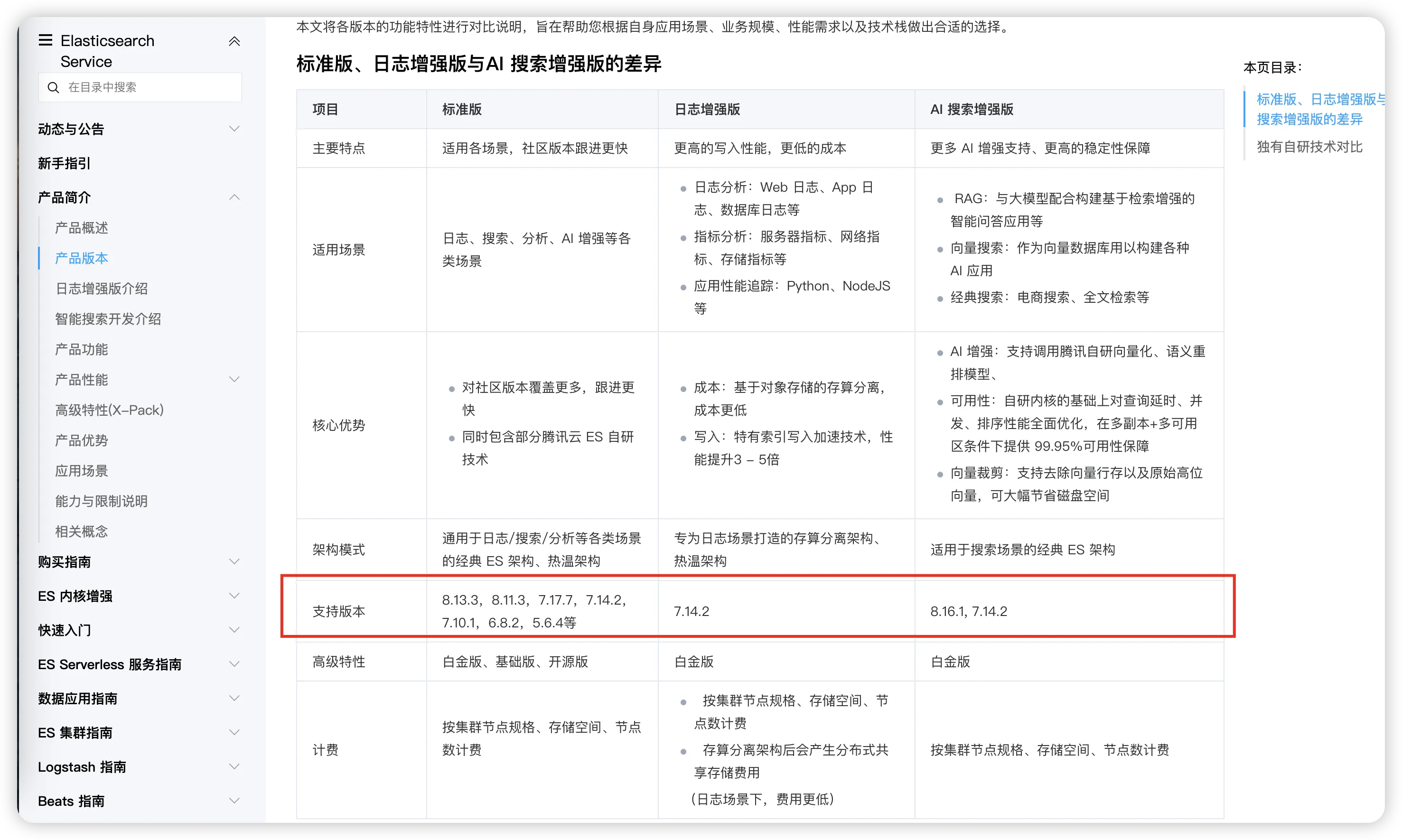
如何选择版本
根据实际使用情况,Elasticsearch最常用的版本是7.x系列中的7.10+版本。如果有 AI 需求的,可直接选择 8.X 版本。
从各家云服务厂商的支持上可以看出:
腾讯云支持的版本:
阿里云提供7.10.x和7.16.x版本
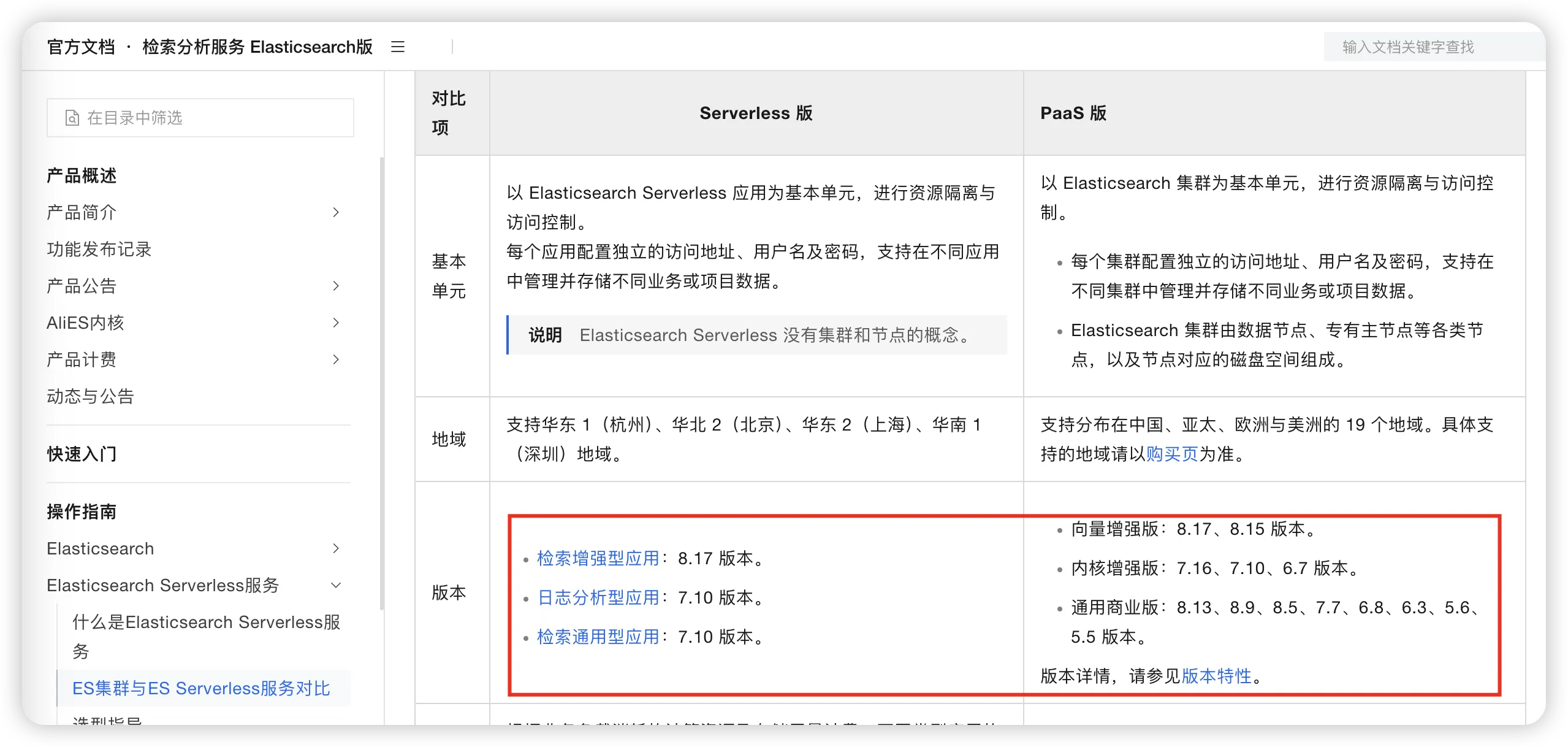
华为云支持7.6.x和7.10.x版本
各大云厂商主要推广7.x版本,稳定性更有保障
执行 docker run 命令
shdocker run -d \
--name elasticsearch \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v /Users/zhangni/liushiGong/docker/elasticsearch/data:/usr/share/elasticsearch/data \
-v /Users/zhangni/liushiGong/docker/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.16.3
参数说明:
-
-d:后台运行容器。
-
--name elasticsearch:为容器指定一个名称。
-
-p 9200:9200 -p 9300:9300:将容器的 9200(HTTP API 端口)和 9300(集群通信端口)映射到宿主机。
-
-e "discovery.type=single-node":设置为单节点模式,简化部署。
-
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":设置 JVM 堆内存大小,请根据你的机器资源调整。
提示
在8.x版本默认开启安全功能,添加 -e "xpack.security.enabled=false" \ 设置禁用,仅用于测试
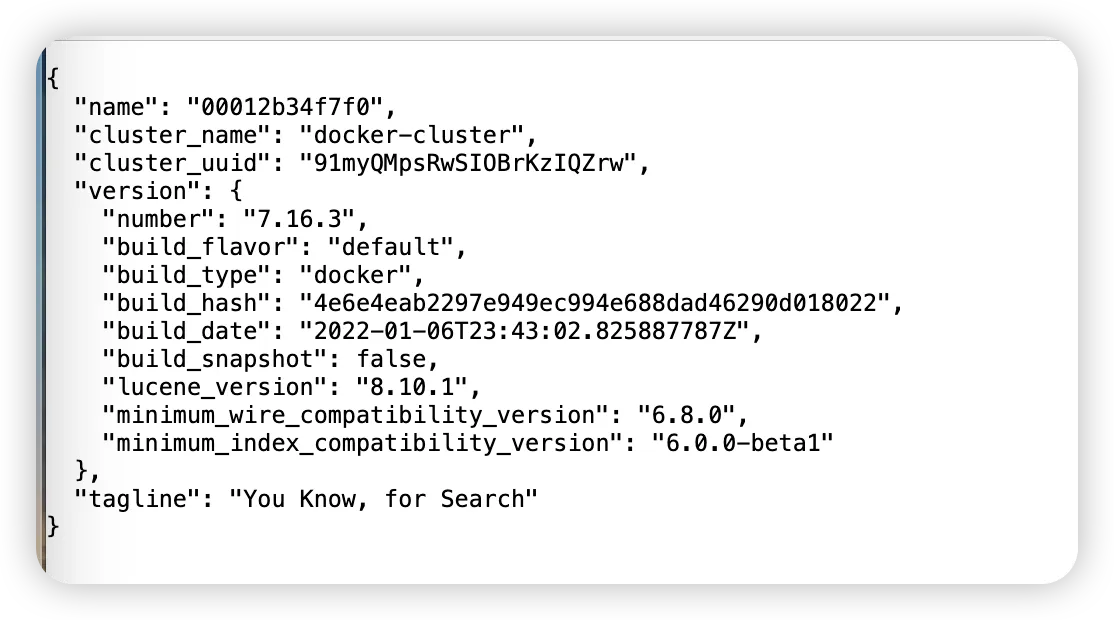
验证安装
容器启动后,在浏览器中访问 http://localhost:9200 ,如果返回一个包含 cluster_name、version 等信息的 JSON 对象,说明 Elasticsearch 已成功启动。
Kibana 的安装
Kibana 是一个开源的数据分析和可视化平台,专为与 Elasticsearch 协同工作而设计。Kibana 提供了一个直观的用户界面,让用户能够快速搜索、分析和可视化存储在 Elasticsearch 中的数据。
拉取镜像,版本与 elasticsearch 保持一致
shdocker pull kibana:7.16.3
执行 docker run 命令
shdocker run -d \ --name kibana \ -e ELASTICSEARCH_HOSTS=http://elasticsearch:9200 \ --network=es-net \ -p 5601:5601 \ kibana:7.16.3
验证安装
容器启动后,在浏览器中访问 http://localhost:5601 , 访问到主界面即安装成功
IK 分词器的安装与配置
成功启动 Elasticsearch 与 Kibana 后,接下来我们安装 IK 分词器插件。
核心前提
核心前提:版本匹配。
IK 分词器的版本必须与你的 Elasticsearch 版本严格对应。例如,如果你的 Elasticsearch 是 7.16.3,那么 IK 分词器也应选择 7.16.3 版本。
下载对应版本的 IK 分词器
你可以在 IK 分词器的 GitHub Releases https://github.com/infinilabs/analysis-ik/releases 页面找到所有版本。
此处使用 7.16.3 版本,复制下面地址,修改为 bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/7.16.3
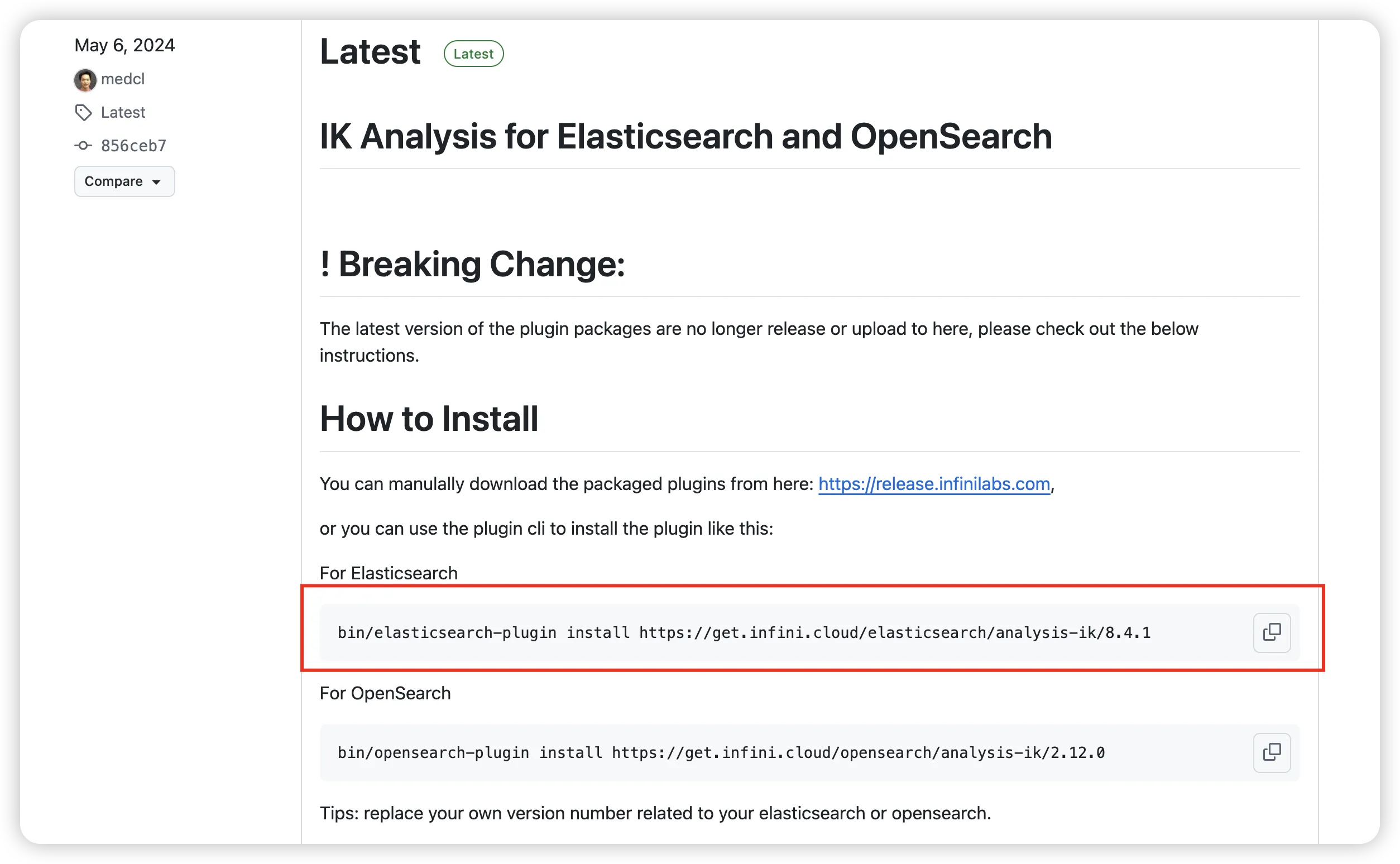
对于 Docker 安装:
shdocker exec -it elasticsearch bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/7.16.3
或者,你也可以将下载好的 ZIP 包复制到容器的插件的挂载目录,使用 elasticsearch-plugin 脚本安装:
bash./bin/elasticsearch-plugin install ./elasticsearch-analysis-ik-7.16.3.zip
重启 Elasticsearch,安装完成后,必须重启 Elasticsearch 服务以使插件生效。
shdocker restart elasticsearch
验证安装
检查 IK 分词器是否加载成功,可以查看插件列表:
bash./bin/elasticsearch-plugin list
如果输出中包含 analysis-ik,则表示安装成功。
IK 分词器的使用与测试
IK 分词器提供了两种主要的分词模式:
-
ik_smart:智能切分,做最粗粒度的拆分,力求准确且无冗余。例如,"中华人民共和国国歌" 会被分为 "中华人民共和国" 和 "国歌"。 -
ik_max_word:最细粒度切分,会穷尽所有可能的词语组合。例如,"中华人民共和国国歌" 会被拆分为 "中华人民共和国"、"中华人民"、"中华"、"华人"、"人民共和国"、"人民"、"共和国"、"共和"、"和"、"国歌" 等。
测试分词效果
点击 Kibana 主界面上的 Dev Tools
接下来我们可以使用 Elasticsearch 的 _analyze API 来测试和对比分词效果。
测试ES自带的默认分词器:
bashPOST _analyze
{
"text": "学习java太棒了"
}
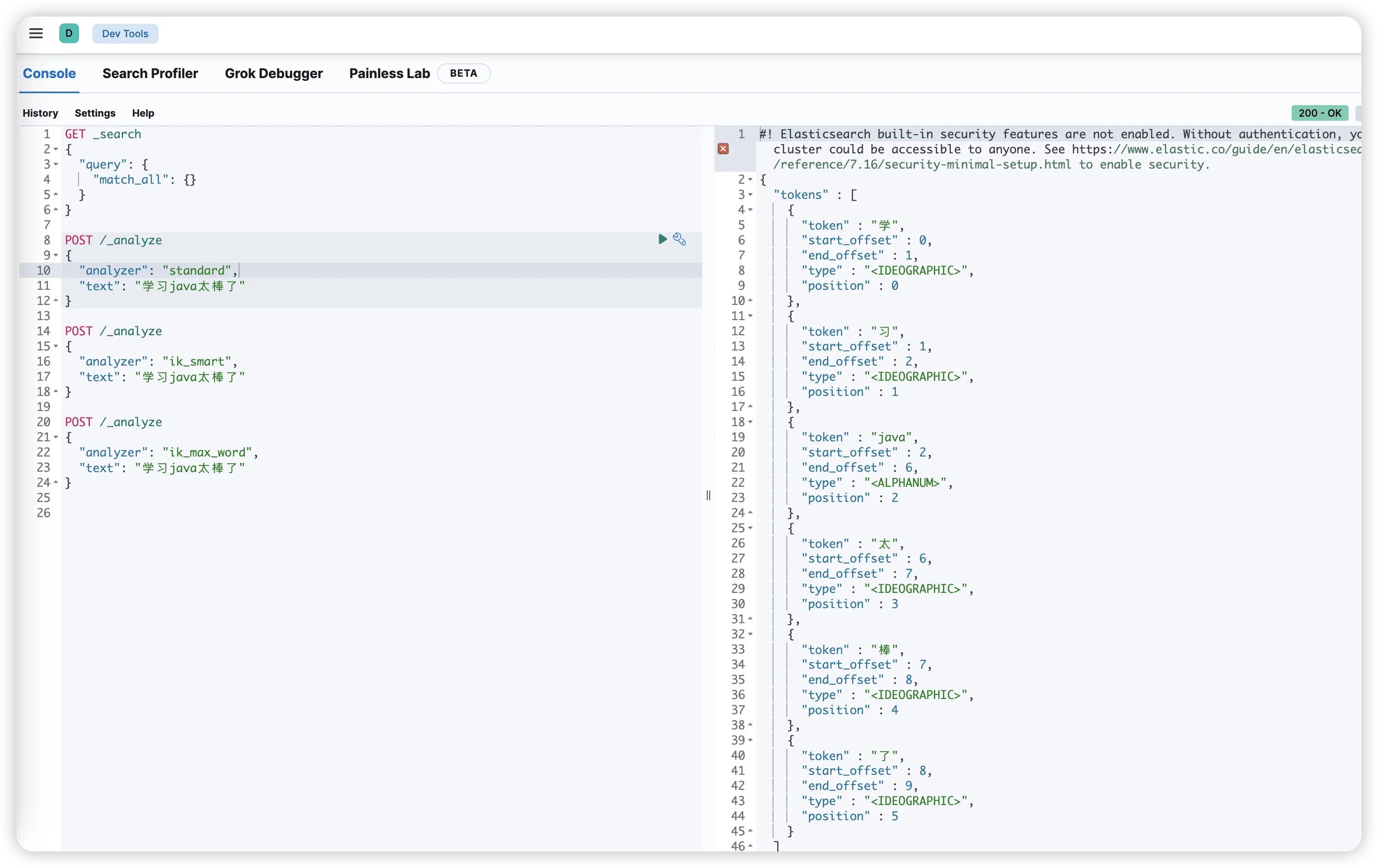
默认分词器可能会将每个汉字单独分开,效果不理想。
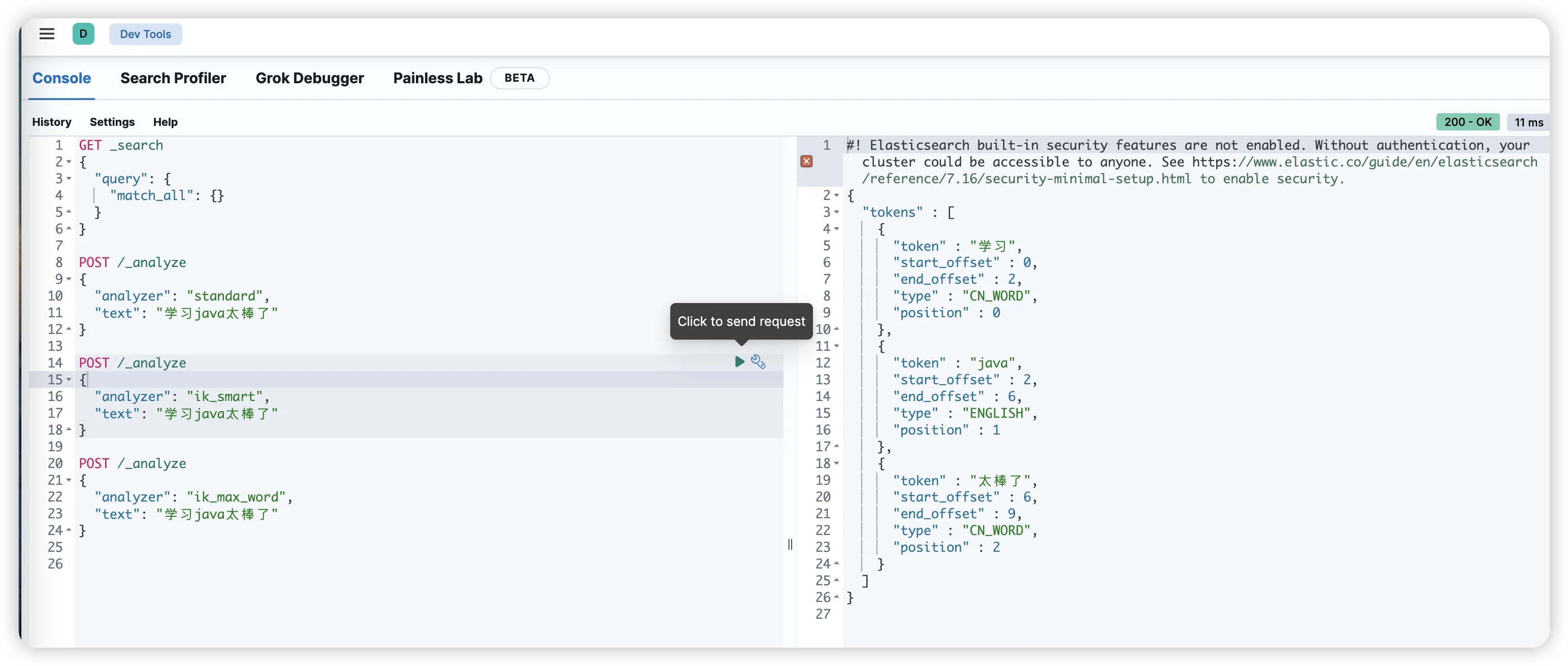
测试 IK 分词器:
bash# 使用 ik_smart 模式
POST _analyze
{
"analyzer": "ik_smart",
"text": "学习java太棒了"
}
sh# 使用 ik_max_word 模式
POST _analyze
{
"analyzer": "ik_max_word",
"text": "学习java太棒了"
}
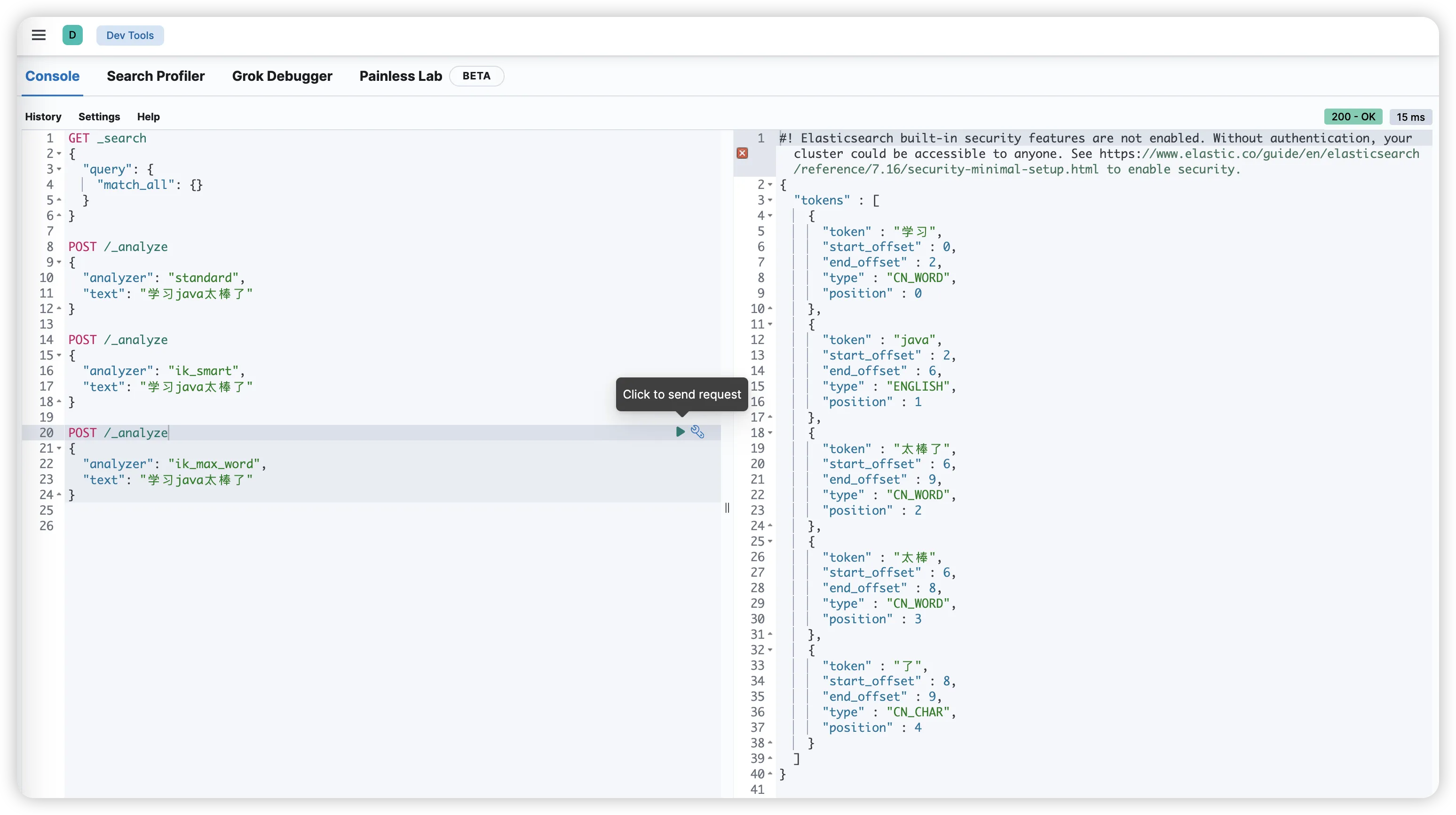
可以清晰地看到 ik_smart 和 ik_max_word 在分词粒度上的区别。
在索引映射中指定 IK 分词器
要让索引的字段真正使用 IK 分词器,你需要在创建索引时,在映射 (Mapping) 中明确指定。
以下是一个创建商品索引的示例,其中 skuTitle 字段使用了 ik_smart 分词器:
bashPUT /gulimall_product
{
"mappings": {
"properties": {
"skuTitle": {
"type": "text",
"analyzer": "ik_smart", # 索引时使用 ik_smart 分词
"search_analyzer": "ik_smart" # 搜索时也使用 ik_smart 分词
},
"brandName": {
"type": "keyword" # keyword 类型适用于精确匹配,如品牌名
}
// ... 其他字段定义
}
}
}
-
analyzer:指定在建立倒排索引(索引化)时对文本进行分词的器。
-
search_analyzer:指定在搜索时,对查询关键词进行分词的器。通常两者设置为一致。
进阶:配置 IK 分词器自定义词库
语言在不断演变,新词、网络用语、专业术语层出不穷。IK 分词器允许你通过自定义词库来识别这些词典中没有的词语,这是其强大和灵活的关键。
配置本地词库
IK 分词器的配置文件位于 plugins/ik/config/ 目录下,核心文件是 IKAnalyzer.cfg.xml。
xml<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
</properties>
-
ext_dict:指定扩展词典文件路径(相对于 config 目录),每行一个词。
-
ext_stopwords:指定扩展停用词词典(如 "的","了"等无实际搜索意义的词)。
创建 custom/mydict.dic 文件,并加入你的新词,例如:
text乔碧罗 汪汪队 区块链
修改配置后,需要重启 Elasticsearch。
配置远程词库(热更新)
对于生产环境,每次更新词库都重启服务是不可接受的。IK 分词器支持通过 HTTP 请求从远程服务器拉取词库,实现热更新。
修改 IKAnalyzer.cfg.xml:
xml<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--远程扩展词典,支持热更新 -->
<entry key="remote_ext_dict">http://your-nginx-server.com/dict/mydict.dic</entry>
<!--远程扩展停止词词典 -->
<entry key="remote_ext_stopwords">http://your-nginx-server.com/dict/stop_words.dic</entry>
</properties>
IK 分词器会定期(默认每分钟)向该 URL 发送 HEAD 请求,如果文件的 Last-Modified 时间戳发生了变化,它会自动重新加载词典,无需重启 Elasticsearch。
你需要在 Nginx 或其它 Web 服务器上托管你的词典文件,并确保 Elasticsearch 服务器能够访问到。


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!