
目录
在实际生产业务中经常会遇到高性能、高并发的查询场景,也就是需要再极短的时间内快速响应用户的查询内容,提高用户的体验性,此时就需要用到搜索技术了,接下来我们将深入了解搜索引擎的核心。
为什么需要搜索引擎?
在如今的互联网应用中搜索无处不在,例如在电商网站的商品列表页中,通常会有按照商品名称进行模糊搜索的需求,要求延迟低,响应迅速。
对于这种场景,最简单的做法就是写一条SQL直接进行模糊匹配,例如:
sqlselect * from sku where name like %手机%;
使用 SQL 模糊查询在小型项目中可以适用,但是如果数据量非常多,那么此方式的性能会急剧下降。
想象一下,你有一个包含数百万乃至数十亿条记录的数据库(比如商品信息、日志数据)。当你想进行 快速、灵活 的搜索时(例如:“查找名称中带有‘手机’且价格在2000-3000元之间的小米商品,并按销量排序”),传统的 SQL LIKE 语句将会变得异常缓慢甚至无法工作。
实际上在互联网的项目中,基本上都是在海量数据中进行搜索,且搜索的关键词多种多样,SQL 语句查询是远远达不到要求的。搜索并不是简单的查询,而是一套复杂且专业的技术方案,可以解决海量数据及多维度搜索的各种难题。
搜索引擎的底层的算法与架构是怎样的?
搜索引擎是根据一定策略、运用特定的计算机程序从互联网上手机信息,对信息进行组织和处理后,将与用户检索相关的信息展示给用户系统。搜索引擎主要分为以下几类:
- 全文检索引擎:对网页的文字、图片、视频和链接等内容进行检索
- 垂直搜索引擎:对网站内垂直领域内容进行搜集和真理,如电商网站中的商品信息搜索
- 元数据搜索引擎:对数据的数据进行搜索和处理,例文章中的字数、文件的大小等,可以看作是对数据整合后再提供给用户的搜索引擎
我们来看下可以实现搜索引擎的算法,实现上都是基于索引来的,相当于我们一本书需要先有目录,才能准确定位的去查询内容,实现的方式主要有 正排索引、倒排索引 两种。
索引概念
被搜索的信息称为 文档,而搜索的词语称为 关键词,文档中包含内容会被拆分成一堆关键词,如果文档包含关键词,那此文档会被检索到,如果不包含关键词在检索时被过滤。
正排索引 or 倒排索引?
正排索引
在搜索层面上,从文档映射到关键词列表的索引叫正排索引,也就是说我们首先对文档添加一个唯一的编号ID,然后对文档进行分词,建立一个文档ID和文档词语对应的哈希表, 同时保存的还有词出现的次数,位置等信息,如下图:

这就是一个哈希表,key就是文档的ID,value就是一个组合结构,里面包含词语,词语频次,出现位置
如果根据文档ID搜索内容效率是极快的,但是如果想要多维度条件查询,那么只能通过全文档扫描才能找出存在对应关键词的文档,效率极低,这个时候我们就需要用到倒排索引了。
倒排索引
按照多维度查询来说,如果我们搜索中包含特定关键词,用正排索引,显然不合适,因为涉及到大量的遍历。那思考一下,我们需要如何调整才能最优呢?是不是可以搜索什么,就去查什么呢?从正排索引进行推导,如果我们能直接搜索关键词,通过关键词查找文档,可以在O(1)时间复杂度找到包含这个关键词的列表,是不是更快捷呢?
其实上面思考的过程,就是倒排索引的实现原理。
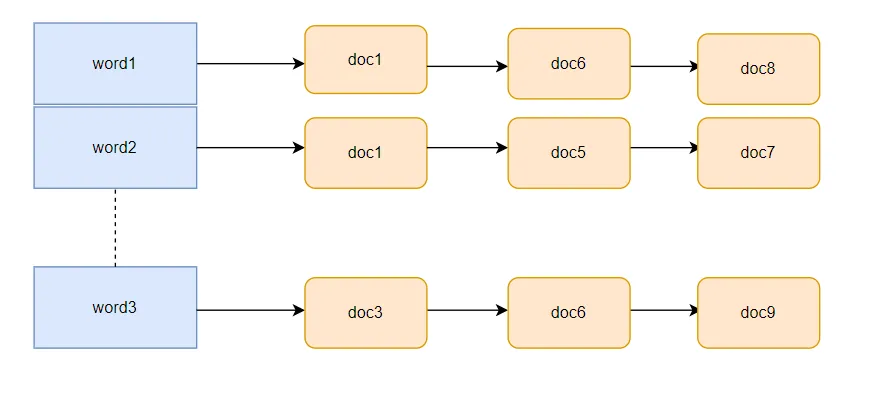
倒排索引的创建过程,整体来说比较简单,主要有以下几步:
-
首先对文档进行编号,且排序,编号顺序就是文档的顺序, 不然就需要对文档进行排序。
-
遍历排序后的文档,对每个文档进行分词,生成《词语,文档ID,位置》的一组组数据,只所以保存位置是为了高亮查询的关键词,有些多个词语查询,如果两个词语靠的更近,得分会更高些。
-
将《词语,文档ID,位置》插入到以词语作为key,《文档ID,位置》作为value的哈希表中。value中也可以多存点信息,比如此在这个文档中出现的次数,这对于我们搜索后排序很有用。最后形成如上图的倒排索引,注意下,上面的倒排索引的value是个链表,而且是排序的链表(id小的在前面)。
如果只是简单的一个词语进行查找,利用倒排索引轻易查出 posting list 获取到文档ID,在通过文档ID把一个个查询出来的文档提取出来就可以了。
但是实际中,我们查询的关键词经常是多个,如果查询即包含 中国 又包含 真气 词语的小说,我们会得到两个 posting list 如下:
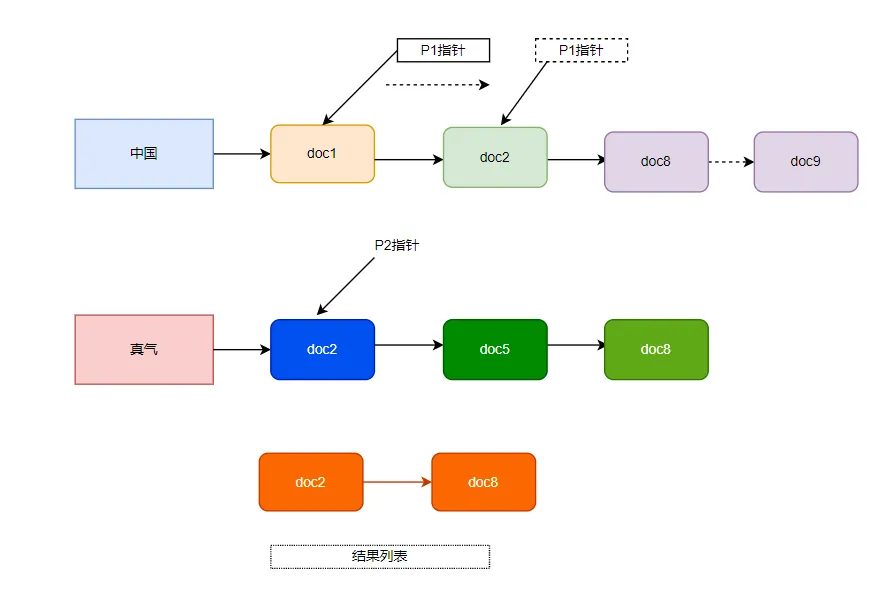
如上图,查询两个关键词,我们得到两个 posting list 然后进行归并,由于文档是有序的,所以归并的过程性能还不错,我们通过两个指针来指向 posting list 的开头,然后根据比较结果移动指针,如果相同,把 docID 取出来放在结果集合中,如果不相等,小的那个指针对后移动,继续进行比较,直到一个 posting list 结束。
这是查询同时包含两个词的情况,还有的情况需要查询包含多个词其中之一的,或者包含A词语,却不含有B词语的无非是两个集合的 并集,交集,差集。
虽然上面这种归并的方法,性能还不错,但是实际工程中,需要用多种手段来优化归并的性能,因为 posting list 很长,如果上述的归并算法是O(m+n),仍然难以性能要求,可以通过调表,哈希表,位图等多种手段优化归并性能。
提示
可以简单理解从文章到关键词叫正排,从关键词到文章叫倒排。以这些方式建的索引分别叫正排索引和倒排索引。
这里面文档可以是一篇文章,也可以是一个网页,还可以是一本小说,这里的文档是我们定义的任何要搜索的信息
Elasticsearch 的前世今生
要实现一个功能完善、性能强大的全文搜索引擎并不简单。在早期出现的一些开源的搜索引擎中最受欢迎的就是 Lucene,使用 Lunene 来实现搜索功能,开发者无需关心底层实现,只需要关注业务本身即可。
但是,随着微服务分布式的崛起,面对高并发的访问,需要搜索引擎能够横向扩展,且每个节点都能以近实时的速度来同步数据,并把请求按多种不同算法分发给具体的服务节点。而 Lunene 是无法满足的,因为它只是一个库,并不具备分布式的能力,因此,开发者基于 Lucene 构建了一套功能强大的搜索引擎 - Elasticsearch

Elasticsearch 是一个开源的分布式搜索和分析引擎,使用 Lucene 作为核心实现了索引和搜索功能,采用 REST 风格,通过简单的 RESTful API 隐藏了 Lucene 的复杂性,从而让全文搜索变得简单。
让我们来拆解这个定义:
- 基于 Lucene:Lucene 是一个顶级的 Java 全文检索库,功能强大但 API 复杂。ES 在 Lucene 之上提供了一个更简单易用的分布式封装。
- 开源:免费使用,社区活跃。
- 分布式:这是 ES 的灵魂。它能将海量数据分割成多个部分(分片),存储在不同的服务器(节点)上,从而实现水平扩展和高可用性。
- RESTful:所有操作,如插入、搜索、删除,都可以通过标准的 HTTP REST API 进行。这意味着你可以用
curl、Kibana 或者任何 HTTP 客户端(如 Java 中的RestTemplate)与之交互。 - 搜索和分析引擎:核心能力是搜索(找到你想要的数据)和分析(从数据中提取有意义的统计信息,如月度销售额趋势)。
核心概念剖析
为什么是“分布式”的?核心架构解析
分布式是 ES 解决海量数据问题的法宝。我们来理解几个核心分布式概念:
集群 (Cluster)
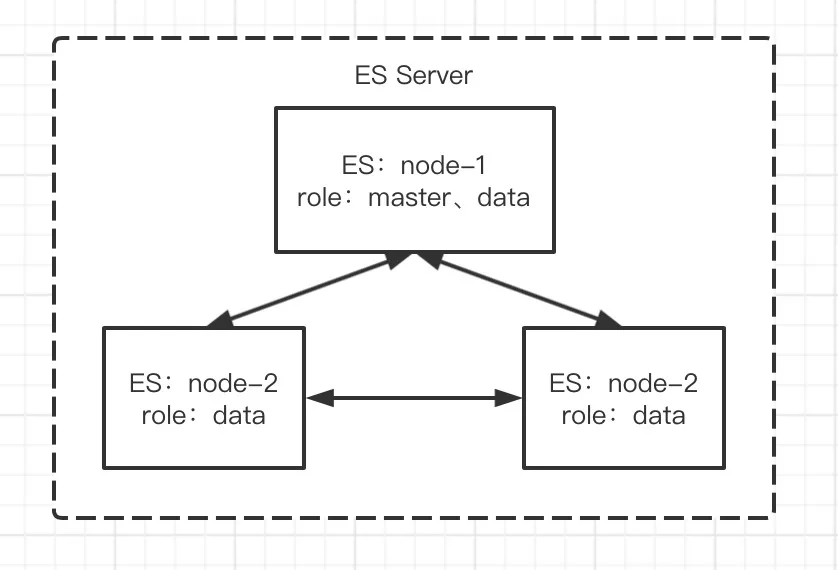
由一个或多个具有相同 cluster.name 的节点组成。它们共同工作,共享数据,并提供跨节点的联合索引和搜索能力。Elasticsearch 采用的是去中心化的架构,在 Elasticsearch 集群中有很多节点,其中一个是主节点,是通过选举产生的。
节点 (Node)
节点即 Elasticsearch 的服务器实例,主要有一下3种类型:
- client_node:做请求分发
- master_node:主节点,所有的新增、删除及数据分片都是由主节点来操作的,同时也提供搜索请求功能
- data_node:只能进行搜索操作,data_node 的数据都是从 master_node 同步过来的。
分片 (Shard)
当一个索引数据量过大时,ES 会将其切分成多个部分,每个部分就是一个分片。每个分片本身就是一个功能完整的 Lucene 索引,可以分布在集群中的任何节点上。
有个分片就可以横向扩展,存储更多的数据,让搜索和分析等操作分布到多台服务器上去执行,从而提升吞吐量和性能。
副本(Replica):
任何一个服务器随时可能出现故障和宕机,此时分片可能会丢失。因此可以为每个分片创建多个副本。副本可以在分片出现故障时提供备用服务,保障数据不会丢失。多个副本一起使用,可以提升搜索操作的吞吐量和性能
分片和副本的区分
分片 和 副本 是 ES 分布式架构的精髓所在。
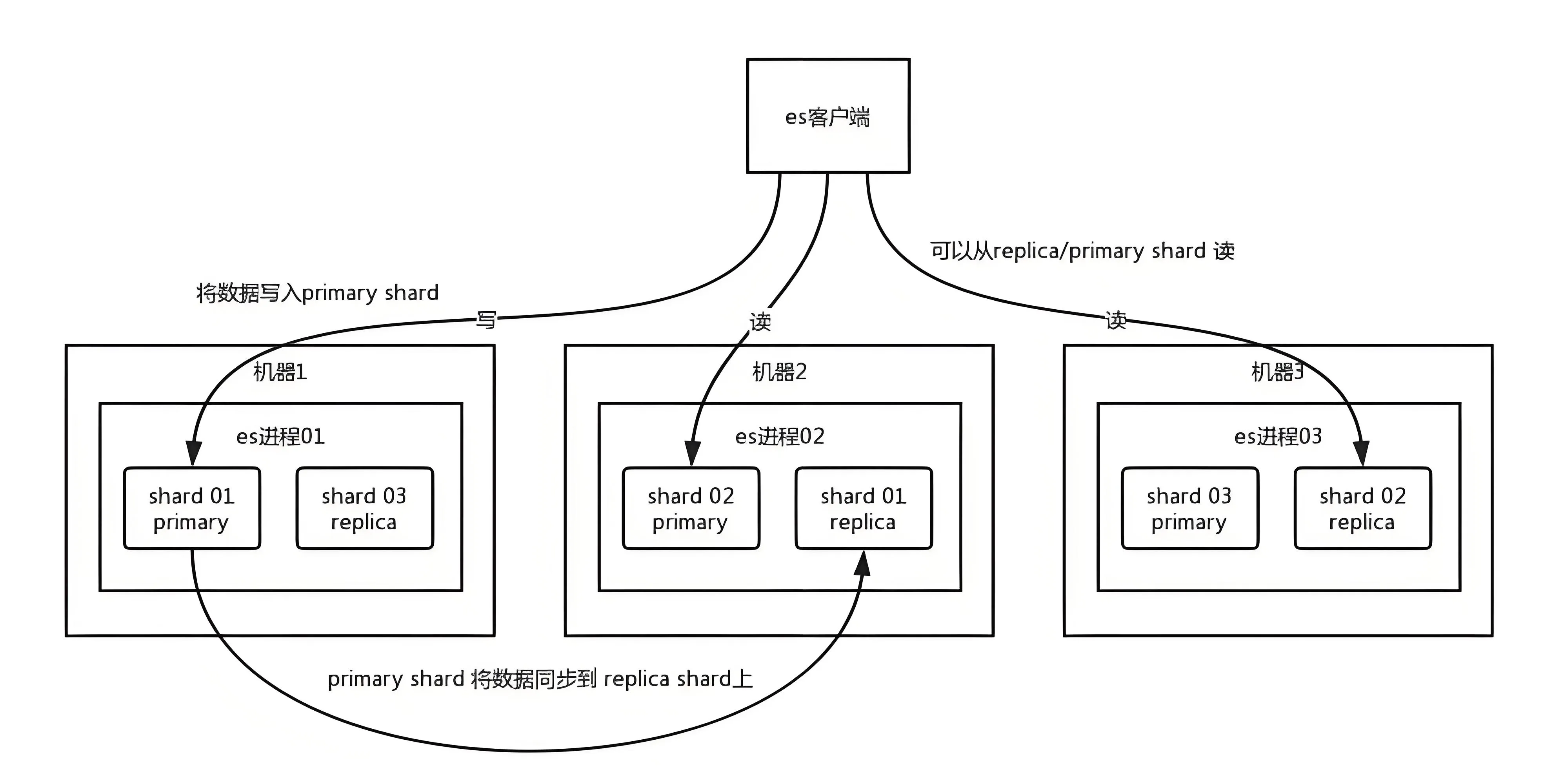
分片 Shard 分为 主分片 Primary Shard 和 副本分片 Replica Shard
Primary Shard 一般简称为分片 Shard; Replica Shard 一般简称为副本 Replica
在分片/节点宕机时,副本分片可以接管工作,防止数据丢失和服务中断。
所有的读操作(搜索、查询)都可以由主分片或副本分片处理,因此增加副本数量可以扩展搜索性能。
一个简单的三节点集群数据分布示意图:
创建索引时的关键决策:
当你创建一个索引时(例如 products),你需要指定:
number_of_shards:主分片的数量。一旦设置,不可修改。number_of_replicas:每个主分片的副本数量。这个值后续可以动态调整。
当存储容量超过 Elasticsearch 所有节点的总容量时,一般在生产中的做法是:重新简历索引(比之前多一点分片),然后导入数据。但是这种做法的缺点是,重新建立索引需要消耗时间。所以通常的做法是进行预分配。通过预分配可以完全避免这个问题。
副本分片是可以动态扩展的。在读取量很大的场景下,适当的扩充副本分片可以增加吞吐量。
如何预估分片容量
预估分片容量涉及的因素较多,例如硬件的容量、文件的大小和复杂度、文档的索引分析方式、运行的查询类型、执行的聚合方式,以及采用的数据模型等等。
预估分片容量的步骤如下:
- 基于“准备用于生产环境的硬件”创建一个拥有单个节点的集群
- 创建一个和生产环境相同配置的索引,但是让它只有一个主分片,没有副本分片。
- 在创建的索引中添加文档
- 运行查询和聚合
- 利用与真实环境相同的方式,将文档全部压缩到单个分片上直到宕机
一个定义了单个分片的容量,就很容易推送出整个索引需要的分片数。用 “需要索引的数据总数” + “上一部分预期的增长” 之和,除以 “单个分片的容量”,结果就是整个索引需要的分片数。
如何数据建模
文档(Document)
文档是 Elasticsearch 的最小存储单元,一个文档可以是一条商品数据,也可以是一个订单数据,通常以 JSON 结构来表示
索引(Index)
索引是存储数据的合集,索引包含一堆相似结构的文档数据。每个索引都有一个唯一的名称,一个集群中可以有多个索引。
Schema-less vs 强 Schema
ES 支持动态映射,你可以在不预定义 Mapping 的情况下直接插入 JSON 文档,它会自动推断类型。但在生产环境中,强烈建议预定义 Mapping,以避免自动推断带来的潜在问题。
为了帮助理解,我们将其与熟悉的关系型数据库(如 MySQL)进行类比:
| Elasticsearch | MySQL | 说明 |
|---|---|---|
| 索引 (Index) | 数据库 (Database) | 一类数据的集合,是最高层级的逻辑容器。 |
| 文档 (Document) | 行 (Row) | 一条完整的数据记录,是 ES 中最基本的数据单元。 |
| 字段 (Field) | 列 (Column) | 文档中的一个属性。 |
| 映射 (Mapping) | 表结构 (Schema) | 定义了索引中每个字段的数据类型(如 text, keyword, integer)和属性。 |
| DSL (Domain Specific Language) | SQL | ES 使用基于 JSON 的 DSL 来进行查询和聚合操作。 |
关于“类型 (Type)”
在 7.x 之前的版本,Index 下面还有 Type 的概念(类似数据库中的表)。但从 7.x 开始,Type 已被废弃,一个 Index 默认只对应一个 _doc Type。这是为了消除关系型数据库类比带来的误导,因为同一个 Index 下不同 Type 的字段会相互影响。
总结
Elasticsearch 是一个分布式搜索和分析引擎,用于处理海量数据的快速检索。分布式是其灵魂,通过分片实现水平扩展,通过副本保证高可用和提升读性能。其数据建模的核心概念可以通过与关系型数据库的类比来帮助记忆,但要注意 Type 已被废弃。


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!