
Press Ctrl+ and K to search
目录
你可能对List/Set/Map有了解,那juc包下的容器与队列呢?本文将全面剖析 Java 并发容器体系,涵盖从传统同步容器到现代高性能并发容器的演进,结合代码示例与性能对比,帮助你构建高并发体系知识
同步容器(JDK 1.0 - JDK 1.2)
核心类与接口
| 类/接口 | 描述 | 线程安全实现方式 |
|---|---|---|
| Vector | 同步版 ArrayList | 所有方法用 synchronized |
| Hashtable | 同步版 HashMap | 所有方法用 synchronized |
| Stack | 同步栈(继承 Vector) | 继承 Vector 的同步 |
| Collections.synchronizedList(List) | 包装普通 List 为同步 List | 内部锁对象同步 |
| Collections.synchronizedMap(Map) | 包装普通 Map 为同步 Map | 内部锁对象同步 |
| Collections.synchronizedSet(Set) | 包装普通 Set 为同步 Set | 内部锁对象同步 |
代码示例:同步容器基本使用
java// Vector 使用示例
Vector<String> vector = new Vector<>();
vector.add("item1");
vector.remove(0);
// synchronizedList 使用
List<String> syncList = Collections.synchronizedList(new ArrayList<>());
syncList.add("safe");
// 迭代时需要手动同步!
synchronized(syncList) {
Iterator<String> it = syncList.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
}
同步容器缺陷分析
性能瓶颈:全表锁导致高并发下性能差
java// Hashtable 的 put 方法(全表锁)
public synchronized V put(K key, V value) { ... }
复合操作非原子性:
java// 错误示例:先检查再操作
if(!vector.contains(item)) {
vector.add(item); // 可能被其他线程插入
}
迭代器弱一致性:
java// ConcurrentModificationException 风险
for(String s : vector) {
vector.remove(s); // 运行时异常
}
注意
现阶段,几乎没有对同步容器的任何应用了
并发容器(JUC 框架)
并发 Map 实现
| 类名 | 数据结构 | 特点 | JDK 版本 |
|---|---|---|---|
| ConcurrentHashMap | 数组+链表+红黑树 | 分段锁/CAS | 1.5+ |
| ConcurrentSkipListMap | 跳表 | 天然有序/无锁读 | 1.6+ |
java// ConcurrentHashMap 基本操作
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
map.put("a", 1);
map.compute("a", (k, v) -> v + 1); // 原子更新
// 高并发统计(线程安全)
map.merge("count", 1, Integer::sum);
// 统计单词频率(线程安全)
ConcurrentHashMap<String, LongAdder> freqMap = new ConcurrentHashMap<>();
words.forEach(word ->
freqMap.computeIfAbsent(word, k -> new LongAdder()).increment()
);
Map实现性能对比(百万次操作)
测试环境:8核 CPU,JDK 17
| 实现类 | 读操作(ms) | 写操作(ms) | 读写混合(ms) |
|---|---|---|---|
| Hashtable | 120 | 450 | 320 |
| Collections.synchronizedMap | 115 | 430 | 310 |
| ConcurrentHashMap | 45 | 85 | 65 |
| ConcurrentSkipListMap | 60 | 210 | 130 |
并发 List/Set 实现
| 类名 | 实现原理 | 适用场景 |
|---|---|---|
| CopyOnWriteArrayList | 写时复制数组 | 读多写少(监听器列表) |
| CopyOnWriteArraySet | 基于 CopyOnWriteArrayList | 读多写少的小规模集合 |
| ConcurrentSkipListSet | 基于 ConcurrentSkipListMap | 有序且并发访问的集合 |
java// CopyOnWriteArrayList 示例
CopyOnWriteArrayList<String> logList = new CopyOnWriteArrayList<>();
// 写操作(复制整个数组)
logList.add("Log entry: " + System.currentTimeMillis());
// 读操作(无锁访问原始数组)
for(String log : logList) { // 迭代器访问快照
System.out.println(log);
}
阻塞队列(BlockingQueue)
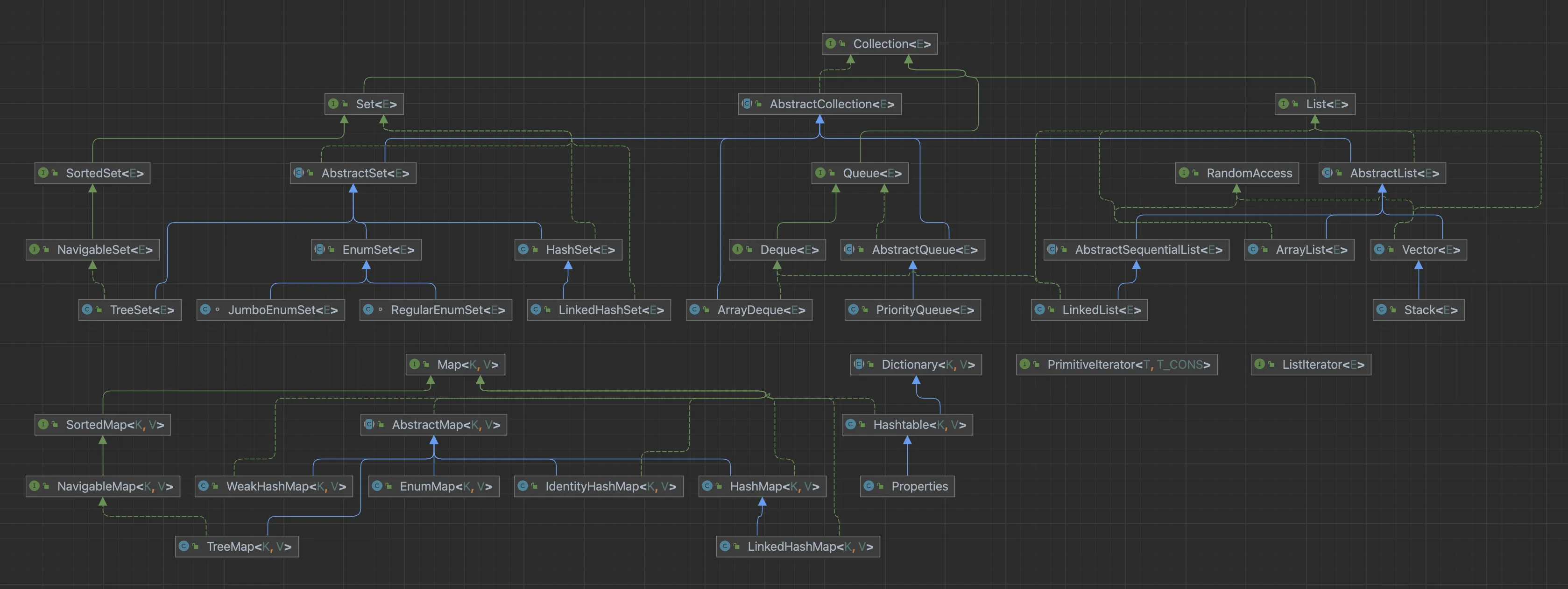
平时我们开发中使用最多的就是List、Set与Map集合,它们的类关系图如下
阻塞队列的方法
生产方法
- add(E) 添加数据到队列,如果队列满了,抛出异常,添加成功返回true
- offer(E) 添加数据到队列,如果队列满了,返回false,添加成功返回true
- offer(E,timeout,unit) 添加数据到队列,如果队列满了,阻塞timeout时间,到期后还不能添加成功,返回false,添加成功返回true
- put(E) 添加数据到队列,如果队列满了,挂起线程,一直等到队列中有位置,再扔数据进去,死等!
消费方法
- remove() 从队列中移除数据,如果队列为空,抛出异常
- poll() 从队列中移除数据,如果队列为空,返回null,么的数据
- poll(timeout,unit) 从队列中移除数据,如果队列为空,挂起线程timeout时间,等生产者扔数据,再获取
- take() 从队列中移除数据,如果队列为空,线程挂起,一直等到生产者扔数据,再获取
检查方法
- element() 检索但不删除此队列的头部,如果队列如空,则抛出异常
- peek() 检索但不删除此队列的头部,如果队列如空,则返回null
阻塞队列的实现
| 队列实现类 | 数据结构 | 特点 |
|---|---|---|
| ArrayBlockingQueue | 数组 | 有界/FIFO/固定容量 |
| LinkedBlockingQueue | 链表 | 可选有界/FIFO/高吞吐 |
| PriorityBlockingQueue | 堆 | 无界/优先级排序 |
| DelayQueue | 优先级堆 | 元素按延迟时间出队 |
| SynchronousQueue | 无缓冲 | 直接传递(生产者-消费者) |
| LinkedTransferQueue | 链表 | 融合阻塞与非阻塞特性 |
ArrayBlockingQueue
-
底层基于数组,是一个有界的先进先出(FIFO)的队列
-
队列的头部是队列中时间最长的元素。队列的尾部是队列中时间最短的元素。新元素插入队列的尾部,队列检索操作获取队列头部的元素
-
方法内部使用 ReentrantLock 来保证线程安全
-
索引
putIndex: 下一个 put、offer 或 add 的项目索引 takeIndex: 下次take, poll, peek 或 remove 的项目索引
代码示例
java// 生产者
BlockingQueue<Task> queue = new ArrayBlockingQueue<>(100);
queue.put(task); // 阻塞直到空间可用
// 消费者
Task task = queue.take(); // 阻塞直到元素可用
// 带超时操作
boolean success = queue.offer(task, 1, TimeUnit.SECONDS);
LinkedBlockingQueue
- 底层是基于单向链表,是一个默认无界的先进先出(FIFO)的队列
- 链表队列通常比基于数组的队列具有更高的吞吐量
- 默认容量长度是 Integer.MAX
java
public LinkedBlockingQueue() { this(Integer.MAX_VALUE); } - 链表节点
java
static class Node<E> { E item; Node<E> next; Node(E x) { item = x; } } - 使用2把 ReentrantLock 分别来控制入队与出队的线程安全
PriorityBlockingQueue
- 基于二叉堆(二叉堆底层基于数组实现)是一个优先级阻塞队列,默认数组长度是11
- 没有自定义比较器,默认基于自然排序
- 方法内部使用 ReentrantLock 来保证线程安全
- 入队的对象必须实现
Comparator<? super E>接口,或者创建 PriorityBlockingQueue 对象时必须指定Comparator<? super E>
DelayQueue
- 无界的延迟阻塞队列,其中元素只有在其延迟过期时才能出队
- 入队的对象必须实现 Delayed 接口 -
DelayQueue<E extends Delayed>javainterface Delayed extends Comparable<Delayed> - 内部基于 PriorityQueue 对时间进行排序存储
- 无界的优先级队列(非阻塞队列 - 没有put、poll( timeunit )、take方法)
- 底层基于二叉堆实现 - 实际是数组
java
public class PriorityQueue<E> extends AbstractQueue<E> - 在比较时,跟根据延迟时间做比较,剩余时间最短的要放在栈顶
- 方法内部使用 ReentrantLock 来保证线程安全
延迟队列实现定时任务:
javaDelayQueue<DelayedTask> delayQueue = new DelayQueue<>();
delayQueue.put(new DelayedTask("task1", 5000)); // 5秒后执行
while(true) {
DelayedTask task = delayQueue.take(); // 阻塞直到到期
task.execute();
}
SynchronousQueue
- SynchronousQueue不存储任何元素
- 直接传递(生产者-消费者)
LinkedTransferQueue
- 实现了TransferQueue接口,而TransferQueue接口是继承自BlockingQueue的
- 使用了一个叫做 dual data structure的数据结构,或者叫做 dual queue,译为双重数据结构或者双重队列。
TransferQueue 实现消息确认:
javaTransferQueue<Message> xferQueue = new LinkedTransferQueue<>();
// 生产者(等待消费者接收)
xferQueue.transfer(message);
// 消费者
Message msg = xferQueue.take();
process(msg);
非阻塞队列
| 队列实现类 | 数据结构 | 特点 |
|---|---|---|
| ConcurrentLinkedQueue | 链表 | CAS 无锁/FIFO/高并发 |
| ConcurrentLinkedDeque | 双向链表 | 双端无锁操作 |
java// 高性能并发队列
ConcurrentLinkedQueue<String> clq = new ConcurrentLinkedQueue<>();
clq.offer("event");
String event = clq.poll();
双端队列(Deque)
| 实现类 | 阻塞类型 | 特点 |
|---|---|---|
| ArrayDeque | 非阻塞 | 数组实现/高效随机访问 |
| LinkedBlockingDeque | 阻塞 | 链表实现/容量可选 |
| ConcurrentLinkedDeque | 非阻塞 | 单向链表无界 CAS 无锁实现 |
java// 双端队列操作
Deque<String> deque = new LinkedBlockingDeque<>(10);
deque.offerFirst("urgent"); // 队首插入
deque.offerLast("normal"); // 队尾插入
String item = deque.pollFirst(); // 队首获取
队列吞吐量对比(每秒操作数)
测试环境:8核 CPU,JDK 17
| 队列类型 | 1线程 | 4线程 | 8线程 |
|---|---|---|---|
| ArrayBlockingQueue | 150,000 | 280,000 | 320,000 |
| LinkedBlockingQueue | 180,000 | 550,000 | 900,000 |
| ConcurrentLinkedQueue | 250,000 | 980,000 | 1,200,000 |
| SynchronousQueue | 140,000 | 480,000 | 750,000 |
最佳实践与选型指南
容器选型决策树
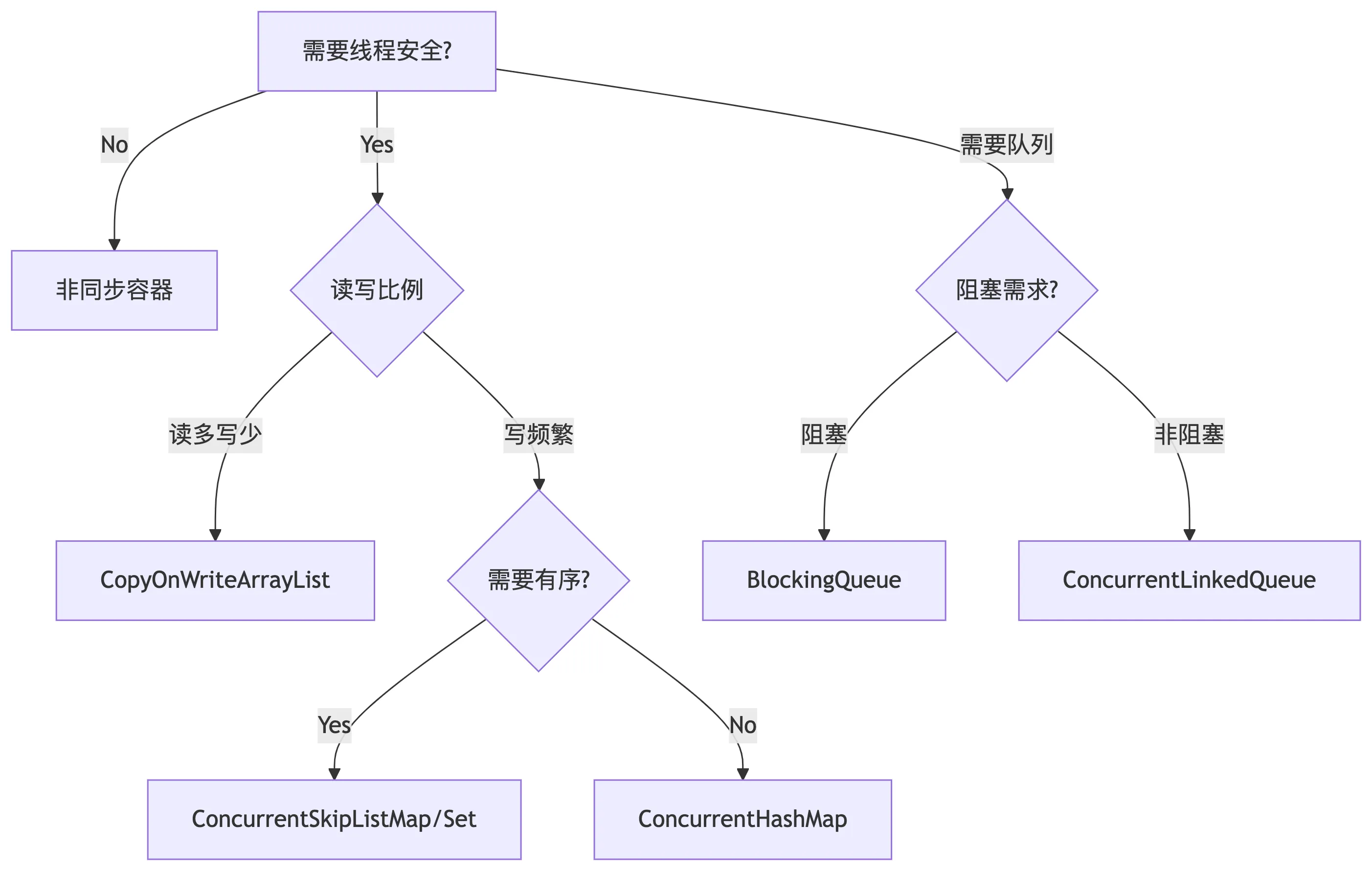
使用禁忌与陷阱
-
错误: 在迭代中修改 CopyOnWriteArrayList
java// 正确:迭代器访问的是快照 for(String item : cowList) { cowList.remove(item); // 允许但不影响当前迭代 } -
注意: ConcurrentHashMap 的弱一致性迭代
javaConcurrentHashMap<String, Integer> map = ...; // 不保证迭代时看到最新修改 map.forEach((k, v) -> System.out.println(k)); -
避免: 无界队列导致 OOM
java// 危险:默认无界可能撑爆内存 BlockingQueue<BigData> queue = new PriorityBlockingQueue<>(); // 推荐:使用有界队列 BlockingQueue<BigData> safeQueue = new ArrayBlockingQueue<>(1000);
总结
| 队列实现类 | 数据结构 | 并发实现 | 特点 |
|---|---|---|---|
| ConcurrentHashMap | 数组+链表+红黑树 | 分段锁/CAS | 并发map,性能极好 |
| ConcurrentSkipListMap | 跳表 | 天然有序/无锁读 | 有序map |
| CopyOnWriteArrayList | 写时复制数组 | synchronized + volatile 数组 | 有序集合 |
| CopyOnWriteArraySet | 数组 | 基于 CopyOnWriteArrayList | 基于数组的无序集合 |
| ConcurrentSkipListSet | 链表 | 基于 ConcurrentSkipListMap | 有序且并发访问的集合 |
| ArrayBlockingQueue | 数组 | ReentrantLock + Condition | 有界/FIFO/固定容量 |
| LinkedBlockingQueue | 链表 | ReentrantLock + Condition | 可选有界/FIFO/高吞吐 |
| PriorityBlockingQueue | 堆 | ReentrantLock + Condition | 无界/优先级排序 |
| PriorityQueue | 二叉堆(数组) | 不是线程安全的 | 有序 |
| DelayQueue | 基于PriorityQueue | ReentrantLock | 元素按延迟时间出队 |
| SynchronousQueue | 无缓冲 | CAS | 直接传递(生产者-消费者) |
| LinkedTransferQueue | 链表 | CAS | 融合阻塞与非阻塞特性 |
| ConcurrentLinkedQueue | 链表 | CAS | CAS 无锁/FIFO/高并发 |
| ArrayDeque | 数组实现 | 不是线程安全的 | 高效随机访问 |
| LinkedBlockingDeque | 链表实现 | ReentrantLock | 容量可选 |
| ConcurrentLinkedDeque | 双向链表 | CAS 无锁实现 | 双端无锁操作 |
- 读多写少 → CopyOnWriteArrayList
- KV 存储 → ConcurrentHashMap
- 有序映射 → ConcurrentSkipListMap
- 任务调度 → PriorityBlockingQueue
- 高吞吐传输 → LinkedTransferQueue
- 极低延迟 → ConcurrentLinkedDeque
通过合理选择并发容器,可提升系统并发能力 3-10 倍,同时降低死锁风险。理解各容器实现原理是构建高性能 Java 应用的基石。
如果对你有用的话,可以打赏哦
打赏


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录