
目录
最近遇到了一些设计相关的面试题,思考了一些边边角角,但是不全面不体系,复盘了下做一下系统化、体系化的梳理,让自己的内力猛增,展示一下雄厚的 “技术肌肉、技术实力”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提,offer自由”。
- 如果要你设计一个灰度发布组件,你会如何设计它的整体架构?
- 你们的灰度发布是如何设计的?发布的时候出现问题,如何 进行版本的回滚?
动态灰度发布
传统的负载均衡策略,如轮询(Round-Robin)或随机(Random),虽然简单高效,却也像一位“一视同仁”的舵手,无法应对日益复杂的生产环境需求。
有一个头疼的灰度场景:一个关键服务即将发布新版本,需要 先让一小部分真实流量进入新版本进行“实弹演习”,验证其稳定性,而不是 “一刀切”式的流量调度方式。当我们需要进行 A/B 测试、蓝绿部署、金丝雀发布(灰度发布)时,传统的负载均衡策略便显得力不从心。

在这我们就需要一个自研 Spring Cloud LoadBalancer 灰度负载均衡组件,实现 服务发现与负载均衡组件,实现接口请求在众多服务实例间精准路由。根据预设的规则,将请求流量按比例、按版本、按区域进行精妙的调度。
接下来我们将从剖析 Spring Cloud LoadBalancer 的核心机制出发,最终亲手实现一个企业级的、基于 Nacos 权重的动态灰度发布策略。这不仅是一次负载均衡器的开发实践,更是一场关于微服务治理、风险控制与平滑发布的深度思考。
大纲
为了更好地规划这次流量探索之旅,我们先通过以下蓝图来了解将要经历的各个阶段。
业务之殇 - 为何需要精细化流控?
- 传统策略的局限:轮询/随机
- 现代发布的需求:A/B测试、灰度发布、优雅停机
生产重器 - 动态灰度发布策略
- 设计理念:Nacos 权重 + 版本元数据
- 源码剖析:实例的选择
实战演练 - 驾驭生产流量
- 定义灰度版本
- 配置 Nacos 灰度规则
- 启动并验证流量
业务之殇 - 为何需要精细化流控?
在微服务实践的早期,我们最常使用的负载均衡策略是轮询。它简单、公平,将请求依次分发给后端的每一个服务实例,如同一个尽职尽责的交通警察,让每条车道都承载相同的车流。然而,随着业务的快速迭代和微服务架构的深入,新的问题开始浮现。
想象一下,你的团队刚刚完成了一个核心交易接口的重大重构。尽管经过了多轮测试,但谁也无法百分之百保证它在真实、复杂的生产流量下能完美运行。此时,最稳妥的方式是进行金丝雀发布(或称灰度发布):先将 1% 的线上流量导入新版本的服务实例,观察其 CPU、内存、错误率等核心指标。如果一切正常,再逐步将流量比例提升到 10%、50%,直至 100%,最终完成新版本的平滑上线。
在这个场景下,轮询或随机策略不灵了。它们无法识别服务实例的版本差异,更无法按需分配流量比例。这使得我们陷入了一个两难的境地:要么承担巨大风险进行全量发布,要么为了追求绝对安全而大大降低发布效率。为了打破这一僵局,我们必须赋予负载均衡器“智能”,让它能够“看懂”服务实例的元数据(如版本、区域、环境等),并根据我们下发的“指令”(流量策略)进行决策。
深入 Spring Cloud LoadBalancer 的内部世界
在构建我们自己的智能负载均衡策略之前,我们必须先理解 Spring Cloud LoadBalancer 的工作原理,因为它是我们所有自定义策略的基石。
自 Spring Cloud 2020.0.0 版本(代号 Ilford)开始,Netflix Ribbon 被正式移除,Spring Cloud LoadBalancer 成为了官方推荐的客户端负载均衡解决方案。它以更简洁、更灵活、全面拥抱响应式编程(Project Reactor)的姿态,为我们提供了强大的扩展能力。
架构三大核心组件Spring Cloud LoadBalancer 的架构可以被精炼地概括为三大核心组件的协作:
-
ReactorServiceInstanceLoadBalancer (负载均衡器):这是负载均衡策略的直接体现者。它的核心职责是接收一个服务实例列表,并根据内部实现的算法(如轮询、随机或我们即将自定义的灰度策略)从中选择一个最合适的实例。
-
ServiceInstanceListSupplier (服务实例列表供应商):它的角色是 客户端 服务实例的“发现者”和“提供者”。它负责与服务发现组件(如 Nacos, Eureka)交互,获取指定服务 ID(serviceId)下所有健康的服务实例列表,并将其提供给负载均衡器。ServiceInstanceListSupplier 还内置了缓存机制,避免了对注册中心的频繁请求。
-
ServiceInstance (服务实例):这是对一个具体服务节点的抽象,包含了该实例的 IP 地址、端口、元数据(metadata)等关键信息。负载均衡器最终选择并返回的就是一个ServiceInstance对象。
核心接口:ReactorServiceInstanceLoadBalancer
负载均衡策略的核心接口是 ReactorServiceInstanceLoadBalancer。
javapublic interface ReactorServiceInstanceLoadBalancer extends ReactorLoadBalancer<ServiceInstance> {
Mono<Response<ServiceInstance>> choose(Request request);
}
它的 choose 方法接收一个 Request 对象(包含了请求上下文),并返回一个 Mono<Response<ServiceInstance>>。
这意味着整个负载均衡过程是异步的、非阻塞的。choose 方法的内部实现,就是负载均衡算法的核心所在。
默认实现:RoundRobinLoadBalancer
Spring Cloud LoadBalancer 的默认实现是 RoundRobinLoadBalancer,它通过一个原子计数器,在所有可用的服务实例中循环选择,实现了轮询策略。
我们的目标,就是通过自定义配置,替换掉这个默认的 RoundRobinLoadBalancer,插入我们自己实现的、更智能的负载均衡器。
工作流程:一次完整的负载均衡之旅
当一个带有 @LoadBalanced 注解的 RestTemplate 或 WebClient 发起请求时,一次完整的负载均衡流程便开始了:
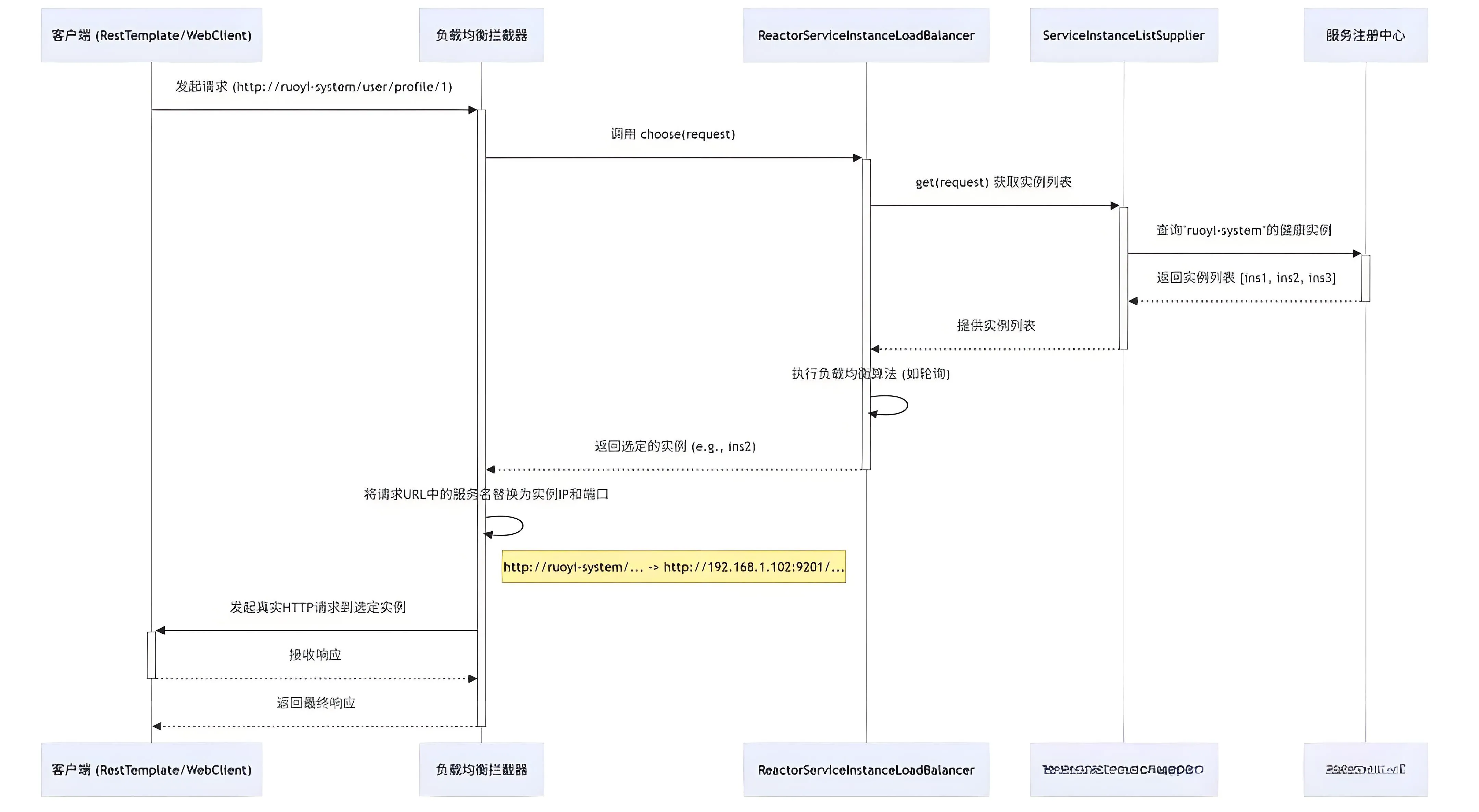
这个时序图清晰展示了Spring Cloud 客户端负载均衡的完整流程,核心是将客户端对 “服务名” 的请求,通过负载均衡机制转换为对具体 “服务实例 IP + 端口” 的请求。
整个流程以 “客户端发起请求” 为起点,以 “客户端接收最终响应” 为终点,共分为 5 个关键阶段,涉及 5 个核心组件的协同工作。
1、发起请求与拦截触发客户端(如使用 RestTemplate 或 WebClient)发起请求,请求 URL 中使用服务名而非具体 IP,请求 地址 例如 http://ruoyi-system/user/profile/1。该请求会被负载均衡拦截器(LBInterceptor) 捕获,拦截器是实现客户端负载均衡的入口。
2、负载均衡器与实例获取拦截器调用负载均衡器(Balancer,如 ReactorServiceInstanceLoadBalancer) 的 choose(request) 方法,请求选择一个合适的服务实例。负载均衡器向服务实例列表供应商(Supplier) 发送 get(request) 请求,获取目标服务的所有可用实例。实例供应商向服务注册中心(Nacos) 发起查询,请求 “ruoyi-system” 微服务的所有健康实例(过滤掉下线或不健康的实例)。
3、实例筛选与算法执行Nacos 返回 “ruoyi-system” 的健康实例列表,例如 [ins1, ins2, ins3]。实例供应商将实例列表传递给负载均衡器。负载均衡器内部执行负载均衡算法(如轮询、随机、权重等),从实例列表中选定一个目标实例(例如 ins2)。
4、 URL 替换与实际请求负载均衡器将选定的实例信息返回给拦截器。拦截器执行关键操作:将请求 URL 中的服务名替换为实例的 IP 和端口。替换前:http://ruoyi-system/user/profile/1替换后:http://192.168.1.102:9201/user/profile/1拦截器使用替换后的真实 URL,向目标服务实例发起 HTTP 请求。
5、 响应接收与返回目标服务实例处理请求后,将响应返回给客户端。拦截器将收到的响应透传给最初发起请求的客户端,整个负载均衡流程结束。
一个简单而实用的自定义负载均衡策略
在深入探讨复杂的灰度发布之前,我们先来分析 一个简单而实用的自定义负载均衡策略——本地优先。
场景:通过调用本地服务提升性能
在一个大型微服务项目中,很多的服务部署在 同一个节点。假设一个 “订单服务”,而它依赖于“用户服务”和“商品服务”。在 rpc 时, 希望“订单服务”调用的 本地启动的“用户服务”, 而不是 其他节点的 “用户服务”和“商品服务”,以方便本地调试并发。
默认的轮询或随机策略无法满足这个需求,它们可能会将请求发送到开发环境的任何一个“用户服务”实例上,导致你的本地调试过程变得极其困难和不可控。
实现:CustomSpringCloudLoadBalancer
为了解决这个问题,一个定制的 本地优先的 `CustomSpringCloudLoadBalancer ,它的核心逻辑非常清晰:
java// org.dromara.common.loadbalance.core.CustomSpringCloudLoadBalancer.java
private Response<ServiceInstance> getInstanceResponse(List<ServiceInstance> instances) {
if (instances.isEmpty()) {
// ...
return new EmptyResponse();
}
// 1. 遍历所有实例
for (ServiceInstance instance : instances) {
// 2. 判断实例的IP是否是本机IP之一
if (NetUtil.localIpv4s().contains(instance.getHost())) {
// 3. 如果是, 立即返回该实例
return new DefaultResponse(instance);
}
}
// 4. 如果没有找到本机实例, 则退化为随机策略
return new DefaultResponse(instances.get(ThreadLocalRandom.current().nextInt(instances.size())));
}
这个实现非常巧妙:
- (1) 它首先获取本地服务器的所有 IPv4 地址。
- (2) 然后遍历注册中心返回的服务实例列表。
- (3) 如果发现某个实例的 host(IP 地址)是本机 IP,就“插队”,直接选择这个实例。
- (4) 如果遍历完所有实例都没有找到本机 IP,说明本地没有启动该服务,此时策略自动“降级”,采用随机算法选择一个远程实例。
通过 CustomLoadBalanceAutoConfiguration将这个自定义负载均衡器设置为默认策略,RuoYi-Cloud-Plus 完美地解决了多团队协同开发时的服务调用问题,极大地提升了开发效率。
自定义 一个 动态灰度发布策略
现在,我们将基于 上面的本地优先负载均衡 代码,一步步构建支持动态权重调整的灰度发布策略。
设计理念:Nacos 权重 + 版本元数据
我们的核心设计思想是:利用 Nacos 作为“指挥中心”
- (1) 服务版本定义:在服务的
application.yml中定义版本号,并在注册到 Nacos 时,将其作为实例的元数据(metadata)
yamlspring:
cloud:
nacos:
discovery:
metadata:
version: v1.1.0
- (2) 灰度规则定义:在 Nacos 配置中心,为需要进行灰度发布的服务定义流量规则。
yamlgray:
loadbalancer:
enabled: true
# 灰度规则
rules:
ruoyi-system:
# 灰度版本号
version: v1.1.0
# 流量权重
weight: 20
-
(3) 智能负载均衡器:创建一个新的负载均衡器
GrayLoadBalancer,它会同时读取 Nacos 注册中心的服务实例列表(及其元数据)和配置中心的灰度规则,然后按权重动态地将流量分配给“灰度版本实例”和“主版本实例”。
核心实现:GrayLoadBalancer
我们创建的 GrayLoadBalancer 是整个灰度策略的核心。其 getInstanceResponse 方法的执行逻辑如下:
javaprivate Response<ServiceInstance> getInstanceResponse(List<ServiceInstance> instances) {
// ... 省略非空判断 ...
// 1. 从配置属性中获取当前服务的灰度规则
GrayRule grayRule = grayLoadBalancerProperties.getRules().get(serviceId);
String grayVersion = grayRule.getVersion();
Integer grayWeight = grayRule.getWeight();
// 2. 根据版本号元数据, 将实例分为灰度组和主版本组
List<ServiceInstance> grayInstances = instances.stream()
.filter(instance -> grayVersion.equals(instance.getMetadata().get("version")))
.collect(Collectors.toList());
List<ServiceInstance> normalInstances = instances.stream()
.filter(instance -> !grayVersion.equals(instance.getMetadata().get("version")))
.collect(Collectors.toList());
// ... 省略其中一组为空的降级逻辑 ...
// 3. 按权重进行流量分配
int random = new Random().nextInt(100);
if (random < grayWeight) {
// 流量走向灰度实例
// 在选定的灰度实例组中再进行一次随机, 避免所有灰度流量打到同一台机器
return new DefaultResponse(grayInstances.get(new Random().nextInt(grayInstances.size())));
} else {
// 流量走向主版本实例
// 同样, 在主版本实例组中进行随机, 保证流量均匀
return new DefaultResponse(normalInstances.get(new Random().nextInt(normalInstances.size())));
}
}
自动装配:让策略 生效(并且动态生效)
为了让 GrayLoadBalancer 能够被 Spring Cloud 框架发现并使用,我们创建了 GrayLoadBalancerAutoConfiguration 。
java@Configuration
// 1. 启用我们定义的灰度配置属性类
@EnableConfigurationProperties(GrayLoadBalancerProperties.class)
// 2. 只有在配置文件中 gray.loadbalancer.enabled = true 时, 该配置才会生效
@ConditionalOnProperty(value = "gray.loadbalancer.enabled", havingValue = "true")
public class GrayLoadBalancerAutoConfiguration {
@Bean
public ReactorLoadBalancer<ServiceInstance> grayLoadBalancer(
Environment environment,
LoadBalancerClientFactory loadBalancerClientFactory,
GrayLoadBalancerProperties grayLoadBalancerProperties) {
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
// 3. 将我们的 GrayLoadBalancer 注入到 Spring 容器, 替换掉默认的负载均衡器
return new GrayLoadBalancer(
loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class),
name,
grayLoadBalancerProperties);
}
}
通过 @ConditionalOnProperty 注解,我们实现了一个“开关”。只有当用户显式地在配置中开启灰度功能时,GrayLoadBalancer 才会覆盖掉默认的 CustomSpringCloudLoadBalancer 或 RoundRobinLoadBalancer,从而实现了对框架的无侵入式扩展。
实现动态灰度的实战演练
理论的价值在于指导实践。现在,让我们一步步完成一次完整的灰度发布流程。
步骤一:准备灰度版本
假设我们正在对 ruoyi-system 服务进行升级。
- 修改代码:完成新功能的开发或 Bug 修复。
- 修改版本号: 在 ruoyi-system 模块的 application.yml 中,将元数据版本号修改为新版本,例如 v1.1.0。
- 打包: 单独打包 ruoyi-system 模块,生成 ruoyi-system.jar。
步骤二:配置 Nacos 灰度规则
登录 Nacos 控制台,找到 ruoyi-system-dev.yml(或对应环境的配置),添加或修改灰度发布配置:
yaml# 灰度发布配置
gray:
loadbalancer:
# 开启灰度功能
enabled: true
# 定义具体服务的规则
rules:
# 为 ruoyi-system 服务配置灰度规则
ruoyi-system:
# 灰度版本的版本号, 必须与jar包中定义的元数据一致
version: v1.1.0
# 分配给灰度版本的流量权重 (0-100), 这里设置为20%
weight: 20
点击“发布”,Nacos 配置中心的这条规则将动态地被我们的 GrayLoadBalancer 感知到。
步骤三:启动并验证流量
1、部署实例:
- 保持原有的 ruoyi-system 服务实例(假设版本为 v1.0.0)运行。
- 将打包好的新版本 ruoyi-system.jar (v1.1.0) 部署并启动。此时 Nacos 中应该能看到两个版本的 ruoyi-system 实例。
2、 验证流量:
为了方便观察, 可以在 ruoyi-system 的某个 Controller 接口中,返回当前实例的版本号。
3、然后使用一个简单的 Shell 脚本来模拟连续请求:
sh#!/bin/bash
# 循环请求100次
for i in {1..100}; do
# 使用 curl 请求网关的接口, -s 表示静默模式
# jq 用于解析JSON并提取version字段
curl -s http://localhost:8080/system/user/profile/1 | jq .data.version
done | \
# 统计各个版本出现的次数
sort | uniq -c | sort -nr
4、 观察结果:执行脚本后,你将看到类似下面的输出:
text81 "v1.0.0" 19 "v1.1.0"
这个结果清晰地表明,在 100 次请求中,约有 80%的流量流向了主版本 (v1.0.0),约有 20%的流量流向了我们新发布的灰度版本 (v1.1.0)。这证明我们的动态灰度发布策略已成功生效!
接下来,我们可以持续观察灰度版本的各项监控指标(如 CPU、内存、错误率等)。如果一切平稳,只需在 Nacos 控制台将weight的值从20逐步调整到50、80,最终调整到100。当权重为100时,所有流量都将进入新版本。此时,我们就可以将旧版本的服务实例安全下线,完成一次平滑、零中断、风险可控的线上发布。
总结与展望
智能负载均衡是微服务治理体系中至关重要的一环。我们实现的灰度发布策略,仅仅是冰山一角。更先进的负载均衡器,可以结合更丰富的维度进行决策,例如:
- 基于请求内容的路由:根据请求头(Header)、参数(Parameter)中的用户信息,将特定用户群体的请求转发到灰度实例。
- 基于性能指标的动态权重:实时采集服务实例的 CPU、内存、响应时间等指标,动态调整实例的权重,自动将流量从性能不佳的实例上移开。
希望本次对 一个自研 Spring Cloud LoadBalancer 灰度负载均衡组件 负载均衡策略的探索,能为你打开一扇通往高级微服务治理的大门,激发你对流量调度架构方案 更深层次的思考与实践。


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!