
目录
第一阶段要夯实AI“话语权”,主要的目标就是掌握与AI团队无障碍沟通的能力。本文学习总结 Python 基础,达到能看懂和修改AI项目代码的程度即可。
Python 概述
开发代码少,精确表达需求逻辑,35个关键字(根据Python版本可能略有不同,这里以Python3.8为例)),7种基本数据类型,语法规则简单,接近自然语言
pythonprint("Hello World!")
等同于
javapublic class Main {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}
Python 2.X 与 Python 3.X 版本对比
| 差异点 | Python2 | Python3 |
|---|---|---|
| 输出方式 | 用 print 关键字,如 print “hello” | 用 print() 函数,如 print("hello") |
| 输入方式 | 用 raw_input 函数 | 用 input() 函数 |
| 字符串编码格式 | 默认采用 ASCII | 默认采用 Unicode |
| 格式化字符串方式 | 用%百分号,如“Hello,%s" %("World") | 用 format() 函数,如 “Hello,{}”.format("World") |
| 源文件的编码格式 | 默认采用 ASCII,因此使用中文时要在源文件开头加上一行 #--coding:utf-8-- | 默认采用 utf-8 |
Python 文档语法
注释
Python 中的注释有2种形式:单行注释与多行注释
python# 单行注释
print("Hello World!")
'''
多行注释
'''
关键字
Python3 共有 35 个关键字,这些关键字有特殊含义,不能用作标识符。
python# 查看所有关键字
import keyword
# 输出:['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
print(keyword.kwlist)
流程控制
流程上的逻辑判断关键字,示例如下
python# if, elif, else - 条件判断
age = 18
if age < 18:
print("未成年")
elif age == 18:
print("刚成年")
else:
print("已成年")
# for, while - 循环
for i in range(5):
print(i) # 输出 0,1,2,3,4
count = 0
while count < 3:
print(count)
count += 1
# break, continue - 循环控制
for i in range(10):
if i == 5:
break # 跳出整个循环
if i % 2 == 0:
continue # 跳过本次循环
print(i) # 输出 1,3
函数定义
python# def - 定义函数
def greet(name):
return f"Hello, {name}!"
print(greet("云泽!~"))
# return - 返回值
def add(a, b):
return a + b
print(add(1, 34))
# lambda - 匿名函数
square = lambda x: x ** 2
print(square(5)) # 输出 25
类和对象
python# class - 定义类
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def introduce(self):
return f"I'm {self.name}, {self.age} years old."
# is - 身份比较
a = [1, 2, 3]
b = a
c = [1, 2, 3]
print(a is b) # True - 同一个对象
print(a is c) # False - 不同对象
异常处理关键字
python# try, except, finally, raise
try:
num = int(input("请输入数字: "))
result = 10 / num
except ValueError:
print("输入的不是有效数字!")
except ZeroDivisionError:
print("不能除以零!")
else:
print(f"结果是: {result}")
finally:
print("程序执行完毕")
# 抛出异常
def validate_age(age):
if age < 0:
raise ValueError("年龄不能为负数")
return age
# 异常调用
try:
print(validate_age(-1))
except ValueError as e:
print(e)
finally:
print("程序执行完毕")
模块和导入关键字
python# import, from, as
import math
from datetime import datetime, date
import numpy as np # 使用别名
print(math.sqrt(16)) # 4.0
print(datetime.now())
变量作用域关键字
python# global, nonlocal
x = 10 # 全局变量
def outer():
y = 20 # 闭包变量
def inner():
global x
nonlocal y
x = 30 # 修改全局变量
y = 40 # 修改闭包变量
inner()
print(f"y = {y}") # y = 40
outer()
print(f"x = {x}") # x = 30
其他重要关键字
python# and, or, not - 逻辑运算符
a = True
b = False
print(a and b) # False
print(a or b) # True
print(not a) # False
# in - 成员检测
numbers = [1, 2, 3, 4, 5]
print(3 in numbers) # True
# with - 上下文管理
with open('file.txt', 'w') as f:
f.write("Hello World")
# yield - 生成器
def count_up_to(n):
i = 1
while i <= n:
yield i
i += 1
for num in count_up_to(5):
print(num) # 输出 1,2,3,4,5
提示
False, True, None: False 和 True 是布尔类型的值,None 表示空值。and, or, not: 逻辑运算符。- and: 与运算,只有所有条件都为True,结果才为True。
- or: 或运算,只要有一个条件为True,结果就为True。
- not: 非运算,取反。
- as: 用于给模块或异常起别名,或者在with语句中为上下文管理器分配别名。
- assert: 断言,用于判断一个表达式,如果表达式为False,则抛出AssertionError。
- async, await: 用于异步编程。
- break: 跳出循环。
- class: 定义类。
- continue: 跳过当前循环的剩余语句,然后继续下一轮循环。
- def: 定义函数。
- del: 删除变量或对象的元素。
- elif, else, if: 条件语句。
- except, try, finally: 异常处理。
- for, in, while: 循环语句。
- from, import: 导入模块。
- global: 声明全局变量。
- is: 判断两个变量是否引用同一个对象。
- lambda: 创建匿名函数。
- nonlocal: 声明非局部变量(用于嵌套函数中)。
- pass: 空语句,占位符。
- raise: 抛出异常。
- return: 从函数返回。
- with: 上下文管理。
- yield: 从生成器函数中返回一个值,并暂停函数的执行。
Python 数据类型
基本数据类型
数字类型 (Numeric)
python# int - 整数
a = 10
b = -5
c = 0
# float - 浮点数
x = 3.14
y = -2.5
z = 2.0
# complex - 复数
comp = 3 + 4j
print(comp.real) # 3.0
print(comp.imag) # 4.0
# 类型转换
num_str = "123"
num_int = int(num_str)
num_float = float(num_str)
布尔类型 (Boolean)
False 和 True 是布尔类型的值,None 表示空值:
python# bool - 布尔值
is_true = True
is_false = False
# 布尔运算
print(True and False) # False
print(True or False) # True
print(not True) # False
# 其他类型转布尔
print(bool(0)) # False
print(bool(1)) # True
print(bool("")) # False
print(bool("Hi")) # True
print(bool([])) # False
print(bool([1])) # True
字符串类型 (String)
python# str - 字符串
s1 = '单引号字符串'
s2 = "双引号字符串"
s3 = """多行
字符串"""
s4 = '''这也是
多行字符串'''
# 字符串操作
name = "Python"
print(len(name)) # 6
print(name.upper()) # PYTHON
print(name.lower()) # python
print(name.startswith("P")) # True
# 字符串格式化
age = 25
message = f"我今年{age}岁" # f-string (推荐)
message2 = "我今年{}岁".format(age) # format方法
message3 = "我今年%d岁" % age # %格式化
# 字符串切片
text = "Hello World"
print(text[0:5]) # Hello
print(text[6:]) # World
print(text[::-1]) # dlroW olleH (反转)
列表类型 (List)
python# list - 列表 (可变)
fruits = ['apple', 'banana', 'orange']
numbers = [1, 2, 3, 4, 5]
mixed = [1, 'hello', 3.14, True]
# 列表操作
fruits.append('grape') # 添加元素
fruits.insert(1, 'pear') # 插入元素
fruits.remove('banana') # 删除元素
popped = fruits.pop() # 弹出最后一个元素
# 列表切片
print(numbers[1:3]) # [2, 3]
print(numbers[:3]) # [1, 2, 3]
print(numbers[2:]) # [3, 4, 5]
# 列表推导式
squares = [x**2 for x in range(5)] # [0, 1, 4, 9, 16]
even_numbers = [x for x in range(10) if x % 2 == 0] # [0, 2, 4, 6, 8]
元组类型 (Tuple)
python# tuple - 元组 (不可变)
coordinates = (10, 20)
colors = ('red', 'green', 'blue')
single_element = (42,) # 注意逗号
# 元组操作
print(coordinates[0]) # 10
print(len(colors)) # 3
print('red' in colors) # True
# 元组解包
x, y = coordinates
print(f"x={x}, y={y}") # x=10, y=20
# 元组与列表转换
tuple_from_list = tuple([1, 2, 3])
list_from_tuple = list(('a', 'b', 'c'))
字典类型 (Dictionary)
python# dict - 字典 (键值对)
person = {
'name': 'Alice',
'age': 25,
'city': 'Beijing'
}
scores = {
'math': 90,
'english': 85,
'science': 92
}
# 字典操作
print(person['name']) # Alice
print(person.get('age')) # 25
person['email'] = 'alice@example.com' # 添加键值对
# 遍历字典
for key in person:
print(f"{key}: {person[key]}")
for key, value in person.items():
print(f"{key}: {value}")
# 字典推导式
square_dict = {x: x**2 for x in range(5)} # {0:0, 1:1, 2:4, 3:9, 4:16}
集合类型 (Set)
python# set - 集合 (无序、不重复)
fruits_set = {'apple', 'banana', 'orange'}
numbers_set = set([1, 2, 3, 4, 5])
# 集合操作
fruits_set.add('grape') # 添加元素
fruits_set.remove('banana') # 删除元素
set1 = {1, 2, 3, 4}
set2 = {3, 4, 5, 6}
print(set1 | set2) # 并集: {1, 2, 3, 4, 5, 6}
print(set1 & set2) # 交集: {3, 4}
print(set1 - set2) # 差集: {1, 2}
print(set1 ^ set2) # 对称差集: {1, 2, 5, 6}
# 集合推导式
even_squares = {x**2 for x in range(10) if x % 2 == 0} # {0, 4, 16, 36, 64}
数据类型检查和使用
python# 类型检查
value = 42
print(type(value)) # <class 'int'>
print(isinstance(value, int)) # True
# 类型转换示例
str_num = "123"
int_num = int(str_num)
float_num = float(str_num)
bool_val = bool(int_num)
list_from_str = list("hello") # ['h', 'e', 'l', 'l', 'o']
# 数据类型的特性比较
# 可变类型: list, dict, set
# 不可变类型: int, float, str, tuple, bool
# 实际应用示例
def process_data(data):
"""处理不同类型的数据"""
if isinstance(data, list):
return [item * 2 for item in data]
elif isinstance(data, dict):
return {k: v * 2 for k, v in data.items()}
elif isinstance(data, (int, float)):
return data * 2
else:
return str(data) * 2
print(process_data([1, 2, 3])) # [2, 4, 6]
print(process_data({'a': 1, 'b': 2})) # {'a': 2, 'b': 4}
print(process_data(5)) # 10
Python3中常见的数据类型
- 数字类型: int, float, complex
- 序列类型: str, list, tuple, range
- 映射类型: dict
- 集合类型: set, frozenset
- 布尔类型: bool
- 二进制类型: bytes, bytearray, memoryview
这些关键字和数据类型是Python编程的基础,熟练掌握它们对于编写高效的Python代码至关重要。
字符串的表示
字符串时一种基本类型,可以使用多种方式表示。
普通字符串
使用单引号(')或双引号(")括起来的字符串,例如:
pythonprint('Hello World!')
print("Hello World!")
原始字符串
使用反斜杠(\)转义特殊字符的字符串,例如:
在Python中,r 表示原始字符串(raw string),原始字符串是一种特殊类型的字符串,在字符串中不会讲反斜杠(\)视为转义字符,而是做为普通字符串原样输出。
pythonprint('Hello \ World!')
print("Hello \r \t \n World!")
三引号字符串
使用三个引号(单引号或双引号都可)括起来的字符串,可包含多行文本,例如:
pythonprint('’‘
Hello
World
!
’‘')
print("“”Hello World!"“”)
提示
三引号字符串中可以用来标识包含多行文本的字符串,用来表示文本字符串
当字符串中包含引号时,为了避免将引号视为转义字符,可以使用三引号字符串
f-string
使用f-string表示格式化字符串,主要作用是简化了字符串格式化的过程,使得代码更加简洁和易读。
f-string使用大写 F 或者 f 作为字符串的前缀,然后在字符串中用花括号 {} 来标记需要插入或替换的表达式。
pythonfor i in range(5):
print(i)
print(f'第{i + 1}个是 {i}')
Unicode 字符串和字节串
Unicode 字符串通常用于表示包含非 ASCII 字符串的字符串,比如包含中文字符或特殊符号的文本。
在python中,通常 Unicode 字符串通常以 u 或者 u'' 做为前缀,Unicode 字符串表示的是字符本身,而不是它们的编码形式。
python# codecs 是Python的一个标准库,它提供了对各种字符串编码的读取和写入的支持
import codecs
# 定义一个包含中文字符的Unicode字符串
text = u'hello,python!'
# 打印字符串
print(text)
# 将字符串写入文件
with codecs.open('output.txt', 'w', encoding='utf-8') as file:
file.write(text)
字节串(Byte String)是一种特殊的数据类型,用于表示二进制数据,字节串以 b 或者bytes 做为前缀,并且包含了一串字符的 ASCII 码表示。
每个字符都是一个字节,因为字符串可以包含多个字节。
python# 创建一个字节串
byte_string = b'hello,python!'
# 打印字节串
print(byte_string)
# 将字节串转化为字符串,需要解码
string = byte_string.decode('utf-8')
print(string)
# 将字符串转换为字节串,需要编码
byte_string = string.encode('utf-8')
print(byte_string)
提示
Python 中的字符串是不可变的,因此对字符串的任何修改都会创建一个新的字符串对象
Python 中提供了丰富的字符串方法,如 len(),str.replace(),str.split()等。此外,Python 还提供了自然字符串(raw string)的概念,可以防止字符串中的转义字符被处理
pythontext = 'Hello World!'
print(len(text))
字符串处理
Python字符串处理是指对Python中的字符串对象:进行各种操作以实现字符申的 分割、替换、格式化、大小写转换 等操作。
为什么我们需要做字符申处理?
-
数据清洗: 在数据处理和分析中,经常需要从原始数据中提取有用的信息。这些信息通常以字符串的形式存在,因此需要对字符串进行各种处理,以提取出需要的信息.
-
数据转换: 有时候需要将字符串转换为其他数据类型,比如将字符申转换为整数或浮点数,或者将字符申转换为日期和时间。
-
字符串格式化: 在编写用户界面、网页或文本文件时,我们可能需要将数据转换为特定的格式,比如在HTML中插人文本或创建表格。
-
字符串匹配: 在文本处理和自然语言处理中,我们经常需要查找字符事中的特定模式或子串
字符串高频处理方法
| 方法 | 用途 |
|---|---|
split() | 按照指定的分隔符将字符串分割成一个列表 |
strip() | 删除字符串头尾指定的字符(默认为空格),返回新字符串 |
replace() | 替换字符串中的指定内容为新字符串,并返回替换后的字符串 |
find() | 查找指定内容在字符串中出现的位置(索引号),若未找到则返回-1 |
lower() | 将字符串中的字母全部转换为小写 |
upper() | 将字符串中的字母全部转换为大写 |
示例
pythonstring = " hello World ! "
# split()
result = string.split(' ')
print(f"分割结果: {result}")
# strip() - 去除首尾空格
strip = string.strip()
print(f"去除首尾空格前的结果: {string}")
print(f"去除首尾空格后的结果: {strip}")
# replace() - 替换字符或子串
replace = string.replace('world', 'Python')
print(f"替换后的结果: {replace}")
# find() - 查找子串位置
position = string.find('hello')
print(f"子串 'hello' 的起始位置: {position}")
# lower() - 转换为小写
lowercase = string.lower()
print(f"转换为小写后的结果: {lowercase}")
# upper() - 转换为大写
uppercase = string.upper()
print(f"转换为大写后的结果: {uppercase}")
其他处理方法
| 方法 | 用途 |
|---|---|
splitlines() | 按照行界符将字符串分割成一个包含各行作为元素的列表,默认不包含行界符 |
lstrip() | 删除字符串左侧的指定字符(默认为空格) |
rstrip() | 删除字符串右侧的指定字符(默认为空格) |
center() | 指定长度的字符串,原字符串居中,左右填充指定字符 |
ljust() | 返回一个指定长度的字符串,原字符串左对齐,使用指定字符(默认为空格)填充至指定长度 |
rjust() | 返回一个指定长度的字符串,原字符串右对齐,使用指定字符(默认为空格)填充至指定长度 |
zfill() | 返回指定长度的字符串,原字符串右对齐,前面填充0 |
index() | 查找指定内容在字符串中出现的第一个位置(索引值),若未找到则报错 |
capitalize() | 将字符串的第一个字符大写,其余字母小写,返回新字符串 |
title() | 将字符串中每个单词的第一个字母大写,其余字母小写,并返回新字符串 |
expandtabs() | 将字符串中的制表符转换为空格,并返回新的字符串 |
translate() | 根据指定的转换表将字符串进行转换,并返回新的字符串 |
示例
python### 其他方法
other = " hello\nworld\n! "
# splitlines() - 按照行界符将字符串分割成一个包含各行作为元素的列表
string_splitlines = other.splitlines()
print(string_splitlines)
# lstrip() - 删除字符串左侧的指定字符(默认为空格)
string_lstrip = other.lstrip()
print(string_lstrip)
# rstrip() - 删除字符串右侧的指定字符(默认为空格)
string_rstrip = other.rstrip()
print(string_rstrip)
# center() - 指定长度的字符串,原字符串居中,左右填充指定字符
string_center = other.center(20, '*')
print(string_center)
# ljust() - 返回一个指定长度的字符串,原字符串左对齐,使用指定字符(默认为空格)填充至指定长度
string_ljust = other.ljust(20, '*')
print(string_ljust)
# rjust() - 返回一个指定长度的字符串,原字符串右对齐,使用指定字符(默认为空格)填充至指定长度
string_rjust = other.rjust(20, '*')
print(string_rjust)
# zfill() - 返回指定长度的字符串,原字符串右对齐,前面填充0
string_zfill = other.zfill(20)
print(string_zfill)
# index() - 查找指定内容在字符串中出现的第一个位置(索引值),若未找到则报错
string_index = other.index('world')
print(string_index)
# capitalize() - 将字符串的第一个字符大写,其余字母小写,返回新字符串
string_capitalize = other.capitalize()
print(string_capitalize)
# title() - 将字符串中每个单词的第一个字母大写,其余字母小写,并返回新字符串
string_title = other.title()
print(string_title)
# expandtabs() - 将字符串中的制表符转换为空格,并返回新的字符串
string_expandtabs = other.expandtabs(4)
print(string_expandtabs)
# translate() - 根据指定的转换表将字符串进行转换,并返回新的字符串
string_translate = other.translate(str.maketrans('world', 'Python'))
print(string_translate)
Python-dotenv
Python-dotenv 是一个Python库,它可以从 .env 文件中读取环境变量,将它们存储在操作系统的环境变量中,使 Python 应用程序可以轻松地访问这些变量。这种方式允许敏感信息(如API密钥、数据库密码等)存储在环境变量中,而不是硬编码在代码中,使得这些信息更加安全并减少泄露的风险。
.env文件是一个纯文本的配置文件,其中包含 key=value 键值键值对,每个 key=value 对占据一行。其中包含的 key-value 键值对表示程序所需要用到的环境变量。
env# MySOL摇库 DATABASE_HOST=localhost DATABASE_NAME=mydatabase DATABASE_USER=myuser DATABASE_PASSWORD=mypassword # 私有key SECRET_KEY=mysecretkey # sk-xxx 使用你白己的 key 替换 OPENAI_API_KEY="sk-xxx" OPENAT_API_BASE="https://apt.fe8.cn/v1"
为什么使用 Python dotenv
-
保护敏感信息
使用 Python-dotenv 将敏感信息存储在环境变量中,而不是硬编码在代码中,可以更加安全地保护这些信息,在Git等版本控制系统中,.gitignore文件可以忽略.env文件,以避免将敏感信息推送到仓库中。这样可以保证代码的安全并减少泄露的风险
-
方便易用
Python-dotenv 提供了一种简单的方式来管理环境变量,并且可以在不同的部署阶段中使用不同的变量,而无需修改代码本身此外,Python-dotenv还可以与其他工具集成使用,比如docker-compose,这样可以轻松实现本地开发和生产环境之间的切换。
-
支持多种变量格式
Python-dotenv 支持多种变量格式,这些格式包括:
key=value,key="value",key-'value'以及key-value# comment.,这些灵活的格式使得 Python-dotenv 非常容易集成到不同的项目中。
如何使用Python-dotenv
-
安装 Python-dotenv
使用pip来安装Python-dotenv.运行命令:
shpip install python-dotenv -
创建.env文件
创建一个.env文件,并将环境变量写人该文件中,每个key=value对应一行
-
将.env文件中的变量加载到系统环境变量中
通过使用
load_dotenv函数,将 .env 文件中的所有变量读取到系统环境变量中,可以在程序中方便地使用这些变量。pythonfrom dotenv import load_dotenv import os # 加载环境变量 load_dotenv('my.env') # 打印环境变量 print(f"全部环境变量: {dict(os.environ)}") # 从配置中读取环境变量 getenv = os.getenv("DATABASE_HOST") print(f"当前环境变量: {getenv}") -
使用 Python-dotenv 进行配置
除了使用环境变量,Python-dotenv还可以与其他库集成使用,比如Flask,在Flask应用程序中,使用Python-dotenv来管理应用程序配置非常简单,可以在应用程序根目录中创建个.env文件,然后在应用程序初始化时使用
load_dotenv数将变量加载到系统中。python# pip install Flask-SQLAlchemy # pip install pymysql import os from dotenv import load_dotenv from flask import Flask from flask_sqlalchemy import SQLAlchemy import pymysql from sqlalchemy import inspect # 安装PyMySQL作为MySQLdb的替代 pymysql.install_as_MySQLdb() # 加载环境变量 load_dotenv('my.env') # 创建Flask应用实例 app = Flask(__name__) # 配置应用密钥 app.config['SECRET_KEY'] = os.getenv('SECRET_KEY', 'your-secret-key') # 配置数据库连接 app.config['SQLALCHEMY_DATABASE_URI'] = ( f"mysql+pymysql://{os.getenv('DATABASE_USER', 'root')}:" f"{os.getenv('DATABASE_PASSWORD', 'password')}@" f"{os.getenv('DATABASE_HOST', 'localhost')}:" f"{os.getenv('DATABASE_PORT', '3306')}/" f"{os.getenv('DATABASE_NAME', 'test')}" ) app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False # 初始化数据库实例 db = SQLAlchemy(app) # 在应用上下文中测试数据库连接 def init_db_connection(): try: with app.app_context(): inspector = inspect(db.engine) table_names = inspector.get_table_names() return True, table_names except Exception as e: return False, str(e) # 初始化数据库连接 db_status, db_result = init_db_connection() if db_status: print(f"数据库连接成功,表列表: {db_result}") else: print(f"数据库连接失败: {db_result}") if __name__ == '__main__': app.run()
认识 FastAPI
FastAPI 是一个用于构建 API 的现代、快速、高性能的web框架,它使用了 Python3.6+ 的类型提示并基于标准的 Python ASGI 工具包。

官方地址:https://fastapi.tiangolo.com/
Python ASGI 工具包
Python ASGI (Asynchronous Server Gateway Interface) 工具包是一种用于构建异步 Web 服务器的标准接口,它允许异步和基于事件的系统之间的通信。
ASGI 工具包的主要租用将 Web 服务器与应用程序之间的通信转换为异步通信,从而提高应用程序的性能和响应速度。
工具包:
-
Hypercom: 一个 ASGI 服务器和 WSGI HTTP 服务器,它支持 HTTP/2WebSocket,具有自动重试、请求超时、连接超时,日志记录等功能。
-
Uvicorn: 一个 ASGI 服务器,它支持HTTP/2和WebSocket,具有自动重试、请求超时,连接超时、日志记录等功能。
-
Sanic: 一个 Python Web 框架,它支持异步请求处理和 WebSocket ,具有路由、中间件、ORM 等功能.
-
Starlette:一个 ASGI 服务器和 WSGI HTTP 服务器,它支持 HTTP/2和WebSocket,具有中间件、路由、异常处理等功能,
FastAPI 的特点
- 快速: FastAPI 的性能极高,可与NodeJS和Go等语言相媲美,是Python框架中最快之一。
- 高效编码: 使用 FastAPI 能够提高开发功能的速度约200%至300%,同时减少人为错误。
- 简单: FastAPI 易于使用和学习,设计的非常直观,可以帮助开发人员快速上手,
- 标准化: FastAPI 完全兼容 API 的开放标准 Open API 和 JSON Schema
- 强大的编辑器支持: FastAPI 具有强大的编辑器支持,可以帮助开发人员更快地进行调试.处处皆可自动补全,从而减少调试时间。
- 自动生成的交互式文档: FastAPI 可以自动生成交互式文档,使开发人员更容易理解其API.
- 代码简洁: FastAPI 的代码非常简洁,可以帮助开发人员减少代码重复并提高代码质量.
- 更少的bug: FastAPI可以帮助开发人员减少大约40%的人为错误,提高代码质量和稳定性。
- 生产可用级别的代码: FastAPI不仅提供了极高的性能和快速的开发速度,还注重代码的质量和稳定性。具有生产可用级别的代码
FastAPI 的使用
首先,安装 FastAPI
shpip install fastapi
对于生产环境,还需要一个 ASGI 服务器,如 Uvicorn 和 Hypercom,接下来我们需要安装一下 Uvicom
pippip install "uvicorn[standard]"
定义 web 接口
pythonfrom fastapi import FastAPI
# 创建FastAPI应用实例
app = FastAPI()
# async 定义web接口
@app.get("/")
def read_root():
return {"message": "Hello, World!"}
接下来我们在终端的目录下输入 unicorn web:app --reload
- web: 文件 web.py
- app: web.py 内创建的对象
app = FastAPI() - --reload: 更改代码后服务器重新启动,仅用于开发

浏览器中访问 http://127.0.0.1:8000 即可直接查看返回结果
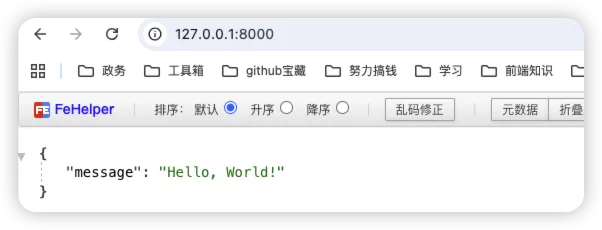
访问 http://127.0.0.1:8000/docs 查看交互式文档
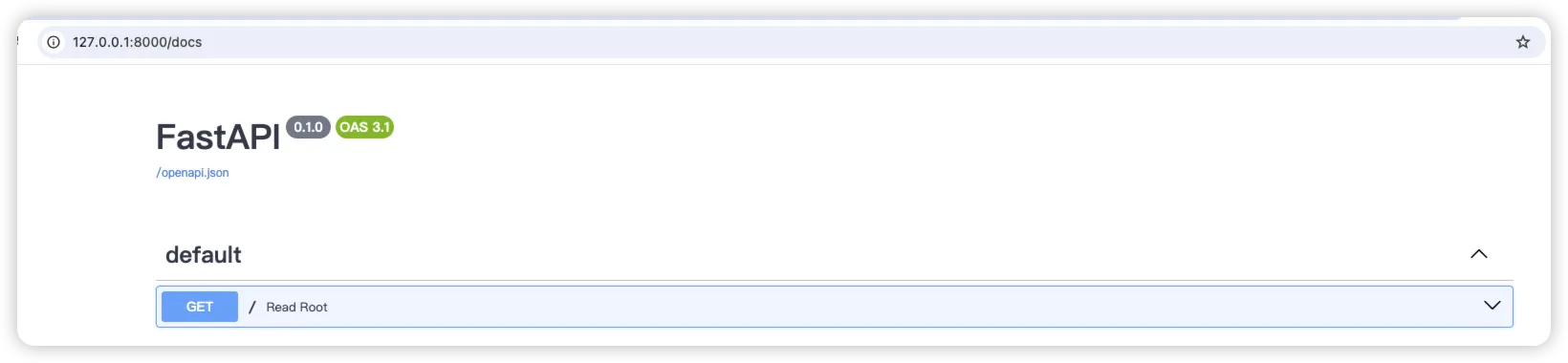
访问 http://127.0.0.1:8000/redoc 查看API文档

FastAPI 进阶应用
使用 FastAPI 构建一个API接口,然后使用 OpenAl 的 GPT 模型提供自然语言处理服务,在课程实践中可以构建一个聊天机器人API.这个AP接收用户输人的文本,然后通过GPT模型进行处理并返回结果
为了实现这种结合,你需要做的工作包括:
- 使用FastAPI创建一一个AP接口,这个接口接收用户输人的文本。
- 将用户输人的文本发送给OpenAl的GPT模型进行处理。
- 解析GPT模型返回的结果并返回给用户。
这样是不是就完成了模型小助手的应用
总结
FastAPI 是一个现代、快速(高性能)的 Python web 框架,用于构建 API。它具有简洁性、高效性和友好界面等特点,广泛用于电子商务,旅游预订和社交媒体等场景。 FastAPI 的实现原理包括代码架构、请求流程和响应机制等方面。
它具有高效的性能和简洁的代码风格,同时需要定的学习曲线和完善的文档。未来, FastAPI 可能会更加智能化、灵活和安全。作为一个新兴的 web 框架, FastAPI 必将在构建 API 方而发挥越来越重要的作用。
未来发展方向:
随者技术的不断发展和应用场景的不断扩大,FastAPI的未来发展方向可能有以下几个方面:
- 更加智能化: FastAPI 可以结合人工智能技术,实现自动化的数据处理、异常处理和安全防护等功能,提高AP1I智能化水平.
- 更加灵活: FastAPI 可以进一-步扩展其路由匹配、依赖注人等机制,使得开发人员能够更加灵活地构建API接口.
- 更加安全: FastAPI 可以加强安全防护机制,包括HTTPS支持、访问控制、身份验证等方面,提高 API 的安全性。
Python 注解
注解在 Python 中是一种 元数据机制,用于在代码中添加额外的信息、函数参数、返回值等.
这些注解可以用于类型检查、注解在Python中通常与类型提示一起使用,以提供关于变量、参数和返回值的预期类型信息。
Python的元数据机制是指用于组织、管理和存储元数据的模型。
在Python中,元数据通常指的是描述数据的信息.这包括数据的类型、值的范围、来源以及其他属性的描述。
通过使用注解,可以增加代码的可读性、可维护性和可靠性。虽然注解不会直接影响函数的运行,但在代码文档化和类型检查方面发挥着重要的作用。
函数入参类型注解
在 Python 中,注解通常使用冒号(:) 来分割表达式和类型,例如,在类方法定义中,可以使用注解来指定参数的类型和返回值的类型:
pythonclass Person:
'''
这个方法接受一个字符串参数 name,返回一个字符串类型的值。
'''
def greet(name: str):
return f"Hello, {name}!"
print(Person.greet('云泽'))
上述方法中接收一个字符串类型的参数 name,并返回一个字符串类型的值,我们使用注解类指定参数和返回值的类型,这个注解是告诉 Python 解释器,name 参数应该是一个字符串类型,返回值也应该是一个字符串类型。
函数返回值类型注解
pythonfrom typing import List
def get_users() -> List[str]:
"""
:return: 这个函数不接收任何参数,返回一个字符串类型的列表
"""
return ['云泽', '小云', '小云2']
print(get_users())
函数不接收任何参数,使用注解来指定返回值的类型。我们导入了 typing 模块中的 List 类型,并将返回值指定为字符串类型的列表。
变量类型注解
pythonclass Person:
'''
指定类属性创建对象时的入参类型
'''
def __init__(self, name: str, age: int):
self.name = name
self.age = 18
person = Person('云泽', 18)
print(person.name)
print(person.age)
在构建对象时,指定入参的类型。
注解的优势
尽管运行时没有强制类型检查,但是使用类型注解还有一些其他好处:
- 通过在代码中明确指定变量的类型和函数的参数类型、返回类型,可以使代码更具可读性,这对于其他开发人员以及个人回顾代码时都很有帮助。
- 如果使用静态类型的检查工具(如mypy),他们会在编译时执行类型检查,并提示潜在的类型错误,这样就可以在开发阶段发现潜在的问题,而无需等到运行时。
- 某些工具和库可能要求或支持类型注解。如果在代码中使用注解,可以与这些工具和库更好的兼容。
Python 注解虽然不是强制性的,但是可以带来很多好处,特别是在大型的软件开发项目中,能够提高代码的可读性和可维护性的错误和缺陷。
注意
Python 是一种动态类型语言,它允许在运行时改变变量的类型。在 Python 中,类型注解只是一种提示,并不会在运行时强制执行类型检查。
- 类型注解主要用于静态类型检查和代码可读性
- 注解并不在运行时强制执行类型检查
- 在静态类型检查时,类型错误会被检测出来并引发警告或错误
字符编码
计算机从本质上来说只认识二进制中的0和1,可以说任何数据在计算机中实际的物理表现形式也就是0和1.
字符编码(Character Encoding)是一种将字符映射为特定二进制模式的系统,它允许计算机以统一的方式存储和处理字符,无论是字母、数字、符号还是特殊字符。
字符编码的目的是为了方便计算机处理和存储文本。常见的字符编码包括 ASCII、UTF-8、GBK 等.
字符编码通常将字符集中的每个字符映射为一个或多个字节(binary digits)。这些字节可以被计算机理解和操作,以实现文本的存储、传输和处理。

常见的字符编码
ASCII
ASCII (American Standard Code for Information Interchange,美国信息交换标准代码)是最常用的字符编码标准之一。它为每个字符定义了一个对应的唯一的二进制编码,使得计算机可以方便地存储、传输和处理文本数据。
ASCII 编码是最早的字符编码标准,它只包含128个字符,包括大小写英文字母、数字、标点符号和控制字符。它的每个字符都对应一个唯一的7位二进制数。
ASCII 编码的用途非常广泛它是计算机内部处理文本数据的基础.例如,在计算机之间传输文本数据时发送方和接收方需要使用相同的字符编码标准才能正确地解析和处理数据. ASCII编码也是很多其他字符编码标准的基础,例如 UTF-8 编码就是基于 ASCII 编码扩展而来的。
Unicode
Unicode 字符编码标准,它旨在为全球范围内的所有字符提供一个统一的编码系统 Unicode 使用一个二进制数值来表示每个字符,这样就可以确保每个字符在全球范围内具有唯一的表示,这种统一的编码方式使得在不同平台、不同语言之间交换和处理文本数据成为可能.
Unicode 编码通常使用一个特定的编码方案来实现.最常见的 Unicode 编码方案是 UTF-8 它是一种可变长度的编码方式。UTF-8 使用1到4个字节来表示一个字符,其中一些字节组合用来表示一些常用的字符,这样可以提高编码效率。应用过程使用了来指示一个 Unicode 转义序列。
pythons = '你好,世界~!'
print(s)
s = 'Hello, \u0041\u0042\u0043\u0044\u0045 World!'
print(s) # 输出:Hello, ABCDE World!
UTF-8
UTF-8 (Unicode Transformation Format-8 bits) 是一种可变长度的 Unicode 编码方案,它用于将字符映射为字节序列。
UTF-8编码具有以下特点:
- 兼容性: UTF-8 完全兼容 ASCII 编码,即 ASCII 字符在 UTF-8 中的编码和 ASCII 相同
- 变长编码: UTF-8 使用1到4个字节来表示一个字符,这使得它可以表示广泛的字符集,包括世界上几乎所有的语言字符
- 向前兼容: UTF-8 的设计使得旧的 UTF-8 编码在新的版本中保持不变,这使得 UTF-8 在不断演进的过程中仍然保持兼容性
python# 定义一个包含UTF-8编码的字符串
text = 'Hello, 世界!'
print(text)
# 将字符串转为UTF-8编码的字节序列
encoded_text = text.encode("utf-8")
print(encoded_text)
# 将UTF-8编码的字节序列解码为字符串
decoded_text = encoded_text.decode("utf-8")
print(decoded_text)
字符编码处理
在使用Python处理字符编码问题时,以下是一些常见的方法:
- 字符串编码与解码:可以使用字符串的 encode() 方法将字符串编码为指定的编码格式,使用 decode() 方法将已编码的字符串解码为指定的编码格式。
- 处理转码错误:在进行编码转换时,如果遇到无法解码或编码的字符,可能会引发
UnicodeDecodeError或UnicodeEncodeError。可以使用 errors 参数来处理这些错误,常见的处理方式包括ignore(忽略错误) 、replace(用占位符代替错误字符)等。
python# 定义一个包含UTF-8编码的字符串
text = 'Hello, 学习!'
# 将字符串转为ASCII编码,忽略无法编码的字符
text1 = text.encode('ascii', 'ignore')
print(text1)
# 将字符串转为ASCII编码,替换无法编码的字符为问号
text2 = text.encode('ascii', 'replace')
print(text2)
- 当文本文件包含中文字符时,可能会出现乱码或其他显示问题。这通常是因为中文字符编码使用了与 Python 解释器不兼容的字符编码。要解决这个问题,可以指定文件的编码方式为 UTF-8,并使用 codecs.open() 函数打开文件。
pythonimport codecs
# 打开包含中文字符的文件,并指定UTF-8编码
with codecs.open('file.txt', 'r', 'utf-8') as file:
content = file.read()
print(content)
- 无法正确读取二进制数据:当尝试使用 codecs.open() 函数读取二进制数据时,可能会出现错误。这是因为 codecs.open() 函数默认将文件视为文本文件。要解决这个问题,可以使用二进制模式打开文件,例如使用 codecs.open() 函数的 encoding=None参数,并使用二进制模式打开文件。
pythonimport codecs
# 打开包含二进制数据的文件,先执行写入操作
with codecs.open('binary_data.bin', 'wb') as file:
# 写入二进制数据
binary_data = b'Hello World This is binary data \xe4\xb8\x96\xe7\x95\x8c'
# 写入二进制数据
file.write(binary_data)
# 以二进制模式打开包含二进制数据的文件,并指定编码方式为None
with codecs.open('binary_data.bin', 'rb', None) as file:
# 读取二进制数据
binary_data = file.read()
# 以二进制模式打开包含二进制数据的文件,并指定编码方式为None
with codecs.open('binary_data.bin', 'rb', 'utf-8') as file:
# 读取二进制数据
binary_data = file.read()
# 输出二进制数据
print(binary_data)
应用字符编码学习建议
- 了解字符编码的基本概念: 学习 Python 应用字符编码之前,你需要了解字符编码的基本概念,这包括 ASCII、 Unicode、UTF-8 等.
- 学习 Python 内置的编码支持: Python 内置了对多种字符编码的支持,包括UTF-8.了解 Python 如何处理字符编码,可以帮助你更好地理解如何应用字符编码。
- 使用 Python 内置的字符编码函数: Python 提供了许多内置的函数来处理字符编码,例如encode()和decode()。了解这些函数以及如何使用它们可以帮助更好地应用字符编码,
- 阅读官方文档和教程: Python 官方文档提供了详细的关于字符编码的说明和教程,阅读这些文档可以帮助你更好地理解 Python 应用字符编码的方式。
- 多多实践: 最好的学习方式是实践.尝试使用 Python 编写包含字符编码的代码,并尝试不同的编码方式来加深对字符编码的理解。
自动化文档
自动化文档生成是指通过使用一些自动化工具, 将代码中的注释和文档字符串转换为可读的文档,以方便开发者、用户或其他相关人员查看和理解代码。
在 Python 中,有很多自动化文档生成工具可以帮助我们实现这一目标, 其中比较流行的包括 Sphinx 和 MkDocs.
Sphinx 是一个用于生成高质量文档的Python工具,它支持多种输出格式,如HTML、PDF等,Sphinx通过读取代码中的注释和文档字符串,以及一些特定的扩展和插件, 来生成详细的文档. 它还支持自动生成API文档、自动创建目录和索引等功能。Sphinx 的语法要求比较严格,但它的文档质量和可定制性都非常高
MkDocs 是一个轻量级的自动化文档生成工具,它使用Markdown语法来编写文档,并将文档生成为静态网站。MkDocs非常简单易用, 可以快速地创建漂亮的文档。它还支持自定义主题和扩展,可以方便地扩展其功能。
它们都可以与 Python 代码紧密结合, 自动从代码中的注释和文档字符串中提取信息,生成可读的文档。这对于提高代码可读性和团队协作效率非常有帮助。
Python 程序异常与处理技巧
常见的错误有以下几种类型
- 语法错误:例如,不正确的缩进,未定义的变量,括号不匹配等
- 运行时错误:例如,尝试访问不存在的文件、内存溢出等
- 类型错误:例如,将字符串与整数相加等
- 逻辑错误:例如,程序没有按照预期的流程执行,条件判断不正确等
- 输入错误:例如,无效的输入,输入类型不正确等
缩进错误
引发错误的原因:
- 未正确地缩进代码块: 在Python中,代码块是通过缩进来区分的,例如,在语句、循环、西数等中,代码块必须正确缩进,否则将会引
- 混合使用不同的缩进方式:在Python中,可以使用空格或制表符(Tab)进行缩进,但是,混合使用这两种方式会导致
IndentationError. 因此,最好在整个项目中保持使用一种缩进方式。 - 错误的缩进级别:在嵌套代码块中,每一级的缩进必须正确对应。如果嵌套的代码块没有正确的缩进级别,将会引发
IndentationError. - 遗漏或添加了空格或制表符:在代码块中,每一行的缩进必须一致.如果某一行多添加或遗漏了空格或制表符,将会引发
IndentationError.
python# 错误案例1 - 缩进错误
for i in range(5):
i = i + 1
print(i)

类型错误
引发错误的原因:
- 将不同类型的值进行算术运算
- 使用 None 进行算是运算或比较
- 将不同类型的值转换为预期类型
- 当函数的期望类型与传递给它的实际类型不匹配时,也会引发 TypeError
python# 错误案例2 - 类型错误
a = 10
b = '20'
print(a + b)
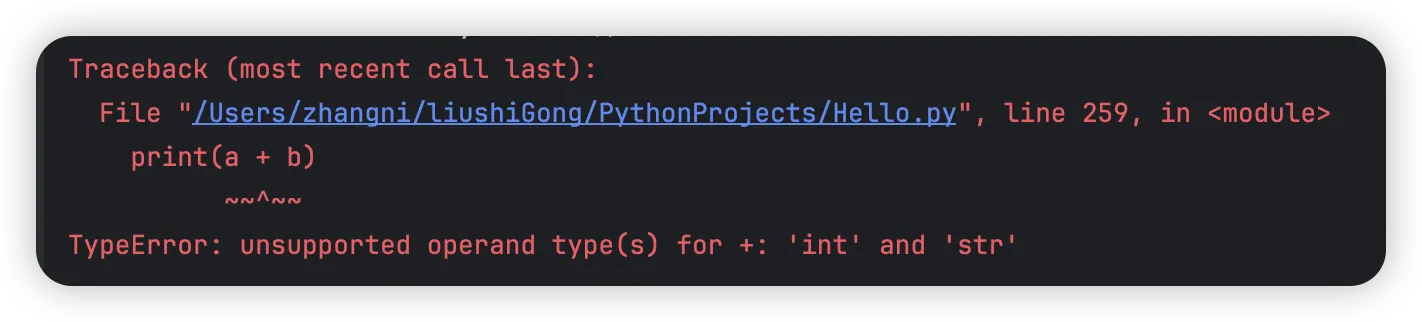
索引错误
引发错误的原因:
- 如果索引超出了序列的范围,将会引发 IndexError
- 尝试从一个空列表或数组中获取元素时,也会引发 IndexError
- 从字典中获取一个不存在的键时,将会引发 KeyError
- 在进行切片操作时,如果切片索引超出范围,将会引发 IndexError
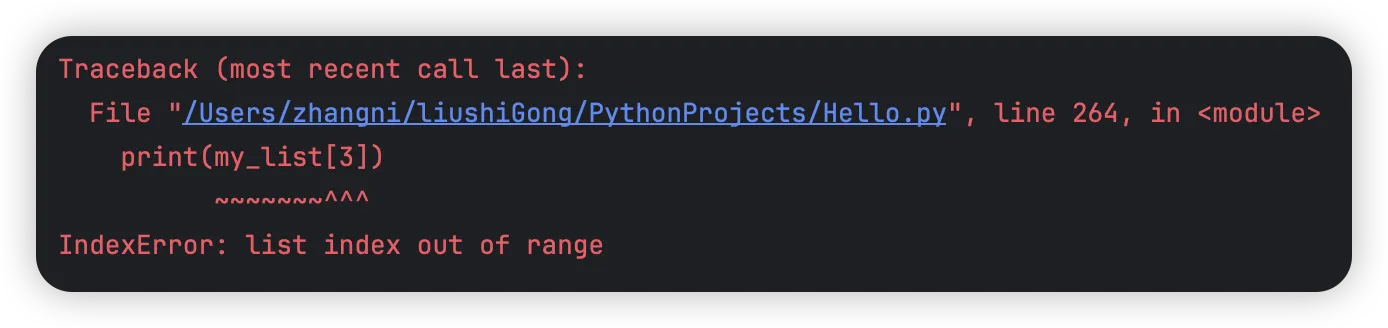
python# 错误案例3 - 索引错误
my_list = [1, 2, 3]
print(my_list[2])
print(my_list[3])
map = {
'name': '云泽',
'age': 18
}
print(map['name'])
print(map['age'])
print(map['sex'])
文件未找到错误
引发错误原因:
- 打开一个文件时,如果路径设置不正确,就会引发 FileNotFoundError
- 打开一个不存在的文件时,会引发 FileNotFoundError
- 在进行文件操作后,确保使用的 close() 方法关闭文件,如果未正确关闭,那么在后续的访问与读取文件时,可能会出现 FileNotFoundError
- 如果 Python 进程没有足够的权限来访问指定的文件,也会引发 FileNotFoundError
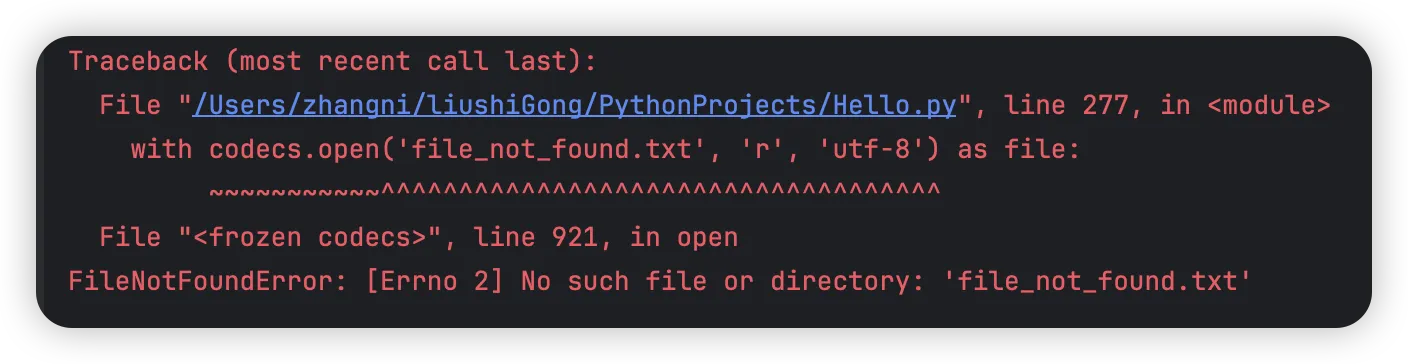
python# 错误案例4 - 文件未找到错误
import codecs
with codecs.open('file_not_found.txt', 'r', 'utf-8') as file:
content = file.read()
print(content)
常见的错误异常
SyntaxError: 语法错误,例如代码编写不符含Python的谐法规则。IndentationError: 缩进错误,例如代码缩进不正NameError: 名称错误,通常是由于引用了来定义或不存在的变量、函数或横块。TypeError: 类型错误。例如使用了不兼容的鼓据类型或对数据类型的操作不正确。ValueError: 值错误,通常是由于传入的参值不符合执期要求。IndexError: 索引错误。通常是由于访问序列(列表、字符审等)时使用了无效的索引或超出了索引范圈。KeyError: 健错误。通常是在字典中查找或访问不存在的键时出现。FileNotFoundError: 文件未找到错误,通常是由于尝试打开或操作不存在的文件时引发。IOError: 输入/输出错误。通常是由于读取或写入文件时发生了错误。ZeroDivisionError: 零游错误,通常是由于降洁运算中除数为零导致的异常。
异常处理方法
try except 是一种 Python 中的异常处理结构,用于捕获和处理在程序执行过程中可能出现的异常。
pythontry:
# 可能引发异常的代码
except TypeError:
# 处理异常
异常信息获取
pythontry:
# 可能引发异常的代码
1 / 0
except TypeError as e:
# 处理异常
print(e)
多种异常类型
pythontry:
# 可能引发异常的代码
except TypeError:
# 处理异常
except ValueError:
# 处理异常
except IndexError:
# 处理异常
非异常的处理
pythontry:
# 可能引发异常的代码
except TypeError:
# 处理异常
else:
# 没有异常时执行的代码
最终处理
pythontry:
# 可能引发异常的代码
except TypeError:
# 处理异常
else:
# 没有异常时执行的代码
finally:
# finally 块中的代码总会被执行
手动抛出异常
pythontry:
# 可能引发异常的代码
except TypeError:
# 处理异常
else:
# 没有异常时执行的代码
finally:
# finally 块中的代码总会被执行
raise ValueError("自定义异常")
try 块中包含可能引发异常的代码,而 except 则用于捕获并处理这些异常,当在 try 块中执行代码时,发生了异常,程序就会跳转到与该异常匹配的 except 块中进行处理。
如果没有适当的 except 块来处理异常,异常则会继续向上传递,直到被顶层的 exception handler (默认为 Python 的默认异常处理器)处理。
如果没有发生异常,则会进入 else 块处理(else 块中的代码,只有在 try 块中的代码都执行成功后,且没有抛出任何异常时,才会执行到)。
finally 语句块是可选的,它包含的代码无论是否发生异常都会被执行,这对于在异常处理后需要执行的后续操作非常有用。
raise 是 Python 中另一个异常处理语句,用于手动引发一个异常,可以使用 raise 语句创建自定义的异常,或者使用内置的异常类型,如 Exception.
JSON 处理
JSON 经常用于与 Web 应用程序进行数据交换,特别是在 RESTful API 中,接下来看下 Python 中是如何处理 JSON 的
JSON转为str
pythonimport json
data = {
"name": "云泽",
"age": 18,
"hobbies": ["reading", "programming"]
}
json_str = json.dumps(data)
print(data)
print(type(data))
print(json_str)
print(type(json_str))
写入JSON文件
pythonimport json
data = {
"name": "云泽",
"age": 18,
"hobbies": ["reading", "programming"]
}
with open('data.json', 'w') as file:
json.dump(data, file)
读取JSON文件
pythonimport json
data = {
"name": "云泽",
"age": 18,
"hobbies": ["reading", "programming"]
}
with open('data.json', 'r') as file:
data = json.load(file)
print(data)
文件I/O
在 Python 中,文件I/O(输入/输出)是指与文件进行交互的过程,这包括读取文件的内容、写入数据到文件以及执行其他与文件相关的操作。
文件I/O 可以通过内置的 open() 函数来实现,这个函数用于打开一个文件,并返回一个文件对象。通过使用文件对象,可以对文件进行各种操作,如读取内容、写入数据等。
写入文件内容
python# 数据写入
with open('hello1.txt', 'w') as file:
file.write('Hello World!~')
file.write('Hello 云泽!')
# 换行写入
with open('hello2.txt', 'w') as file:
file.write('Hello World!~\n')
file.write('Hello 云泽!')
with open('hello3.txt', 'w') as file:
for i in range(5):
file.write(f'Hello {i}!~\n')
读取文件内容
pythonwith open('hello1.txt', 'r') as file:
print(file.readline())
with open('hello2.txt', 'r') as file:
print(file.read())
with open('hello3.txt', 'r') as file:
for line in file:
print(line)
关闭文件
在使用完文件后,应该使用 close() 方法关闭文件,以释放资源,但是,在使用 with 语句时,Python 会自动处理文件的关闭操作,因为不需要手动调用 close() 方法
pythonwith open('hello.txt', 'r') as file:
print(file.read())
file.close()


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!